Unmasking Biomarkers: Correcting Menstrual Cycle Bias to Revolutionize Women's Health Research
This article addresses the critical, yet often overlooked, issue of menstrual cycle bias in biomedical research, which has historically masked true disease-specific biomarkers and hindered progress in women's health.
Unmasking Biomarkers: Correcting Menstrual Cycle Bias to Revolutionize Women's Health Research
Abstract
This article addresses the critical, yet often overlooked, issue of menstrual cycle bias in biomedical research, which has historically masked true disease-specific biomarkers and hindered progress in women's health. We explore the foundational problem of how the endometrial molecular biology of the cycle acts as a major confounding variable, leading to significant knowledge gaps. Methodological solutions are presented, including statistical correction techniques and improved study design guidelines, which have been proven to dramatically increase the discovery of novel candidate genes for conditions like endometriosis and recurrent implantation failure. The discussion extends to troubleshooting common implementation challenges and validating the enhanced accuracy and statistical power achieved through bias correction. Aimed at researchers, scientists, and drug development professionals, this synthesis provides a roadmap for integrating menstrual cycle considerations to unlock more precise, effective, and personalized diagnostic and therapeutic strategies for uterine disorders and beyond.
The Hidden Confounder: How Menstrual Cycle Progression Masks True Biomarkers
What is the "menstrual cycle confounding" problem in endometrial biomarker studies?
The human endometrium is a dynamic tissue that undergoes profound hormonal regulation and changes throughout the menstrual cycle [1]. This natural progression has a substantial influence on gene expression and molecular profiles [1]. When researchers attempt to identify biomarkers for endometrial disorders (such as endometriosis or recurrent implantation failure), the strong molecular signature of the menstrual cycle phase can mask the more subtle molecular differences caused by the pathology itself [1]. Consequently, it becomes unclear whether observed changes in transcriptomic or proteomic studies reflect variations related to the disorder, to menstrual cycle progression, or to both. This confounding effect is a significant source of poor reproducibility and lack of robust, translatable biomarkers in endometrial research [1].
Quantitative Evidence: The Scope of the Problem
To what extent does the menstrual cycle actually affect molecular data?
Multiple studies have quantified the substantial impact of the menstrual cycle on molecular biomarkers. The table below summarizes key findings from the literature.
Table 1: Documented Impact of Menstrual Cycle on Molecular Biomarkers
| Study Focus | Key Finding | Magnitude of Effect | Reference |
|---|---|---|---|
| Endometrial Transcriptomics | Genes identified as differentially expressed after correcting for menstrual cycle bias | 44.2% more genes discovered on average | [1] |
| Serum Biomarkers (General) | Analytes varying with sex and female hormonal status (OC use, menstrual cycle phase, menopause) | 117 of 171 (68%) analyzed serum analytes showed significant variation | [2] |
| Serum Biomarkers (Premenopausal Women) | Molecules differing between menstrual cycle phases (e.g., follicular vs. luteal) | 66 of 171 serum analytes varied significantly | [2] |
| Cardiometabolic Biomarkers | Women with elevated cholesterol (≥200 mg/dL) warranting therapy | Nearly twice as many in follicular phase vs. luteal phase (14.3% vs. 7.9%) | [3] |
| Cardiometabolic Biomarkers | Women classified with elevated CVD risk (hsCRP >3 mg/L) | Nearly twice as many during menses vs. other phases | [3] |
Troubleshooting Common Experimental Issues
FAQ: We balanced our case and control groups for cycle phase. Is that sufficient?
Simply balancing group proportions is a good start but is often insufficient to fully remove the confounding effect. Even in studies where the proportion of samples from different endometrial stages was balanced between case and control groups, a significant number of candidate genes remained masked [1]. The inherent molecular variability within a phase (e.g., early vs. late secretory phase) can still introduce noise. A more robust statistical correction for the cycle phase as a continuous or multi-level categorical variable is recommended to increase the statistical power for discovering true pathology-related biomarkers [1].
FAQ: What is the risk of false discoveries if we ignore this confounder?
The risk is very high. Simulation studies have demonstrated that when patient and control groups are not matched for sex, up to 40% of measured analytes can be false discoveries [2]. Similarly, when groups of premenopausal females are not matched for oral contraceptive pill use—another major modifier of hormonal status—up to 41% false discoveries can occur [2]. Even less severe imbalances (e.g., 20% vs. 60% oral contraceptive use in controls vs. patients) can cause false discoveries in about 15% of molecules [2].
FAQ: Besides the endometrium, does this affect other research areas?
Absolutely. The confounding effect of the menstrual cycle extends far beyond endometrial studies. For instance, in mental health research, the severity of symptoms in conditions like schizophrenia fluctuates with hormonal status, with improvements noted during high-estrogen phases of the cycle [4]. Furthermore, serum biomarkers for cancer, cardiovascular disease, and metabolic disorders are also significantly influenced by the menstrual cycle, threatening the validity of studies across biomedical fields if not properly accounted for [2] [3] [5].
Experimental Protocols for Bias Correction
Detailed Methodology: Correcting for Menstrual Cycle Effect in Transcriptomic Data
The following protocol, adapted from a 2021 systematic review, provides a robust method for removing menstrual cycle bias from gene expression data [1].
Step 1: Pre-processing and Exploratory Analysis
- Technology-Specific Normalization: Use appropriate R packages for your platform.
- Affymetrix Microarrays: Use the
affyR package (v.1.52.0 or later). - Agilent/Illumina Platforms: Use the
limmaR package (v.3.30.13 or later) for normalization between samples (e.g., using quantile normalization). - RNA-Seq Data: Use the
edgeRR package (v.3.16.5 or later) for low-count filtering and normalization.
- Affymetrix Microarrays: Use the
- Annotation: Annotate probesets to gene symbols using a package like
biomaRt(v.2.30.0). - Batch Effect Detection: Perform exploratory analysis (e.g., Principal Component Analysis) to detect other batch effects (sequencing run, slide). Correct for these using linear models in
limmabefore addressing the menstrual cycle effect.
Step 2: Menstrual Cycle Effect Correction
- Use the
removeBatchEffectfunction from thelimmaR package. This function is based on linear models and is recommended for correcting known batch effects while preserving the group differences of interest (e.g., case vs. control). - In the function call:
- Specify the menstrual cycle phase of each sample (e.g., proliferative, early secretory, mid-secretory) as the
batchargument to be removed. - Define the
designmatrix based on the condition you wish to preserve (e.g.,~ Uterine_DisorderwhereUterine_Disorderis a factor indicating case or control status).
- Specify the menstrual cycle phase of each sample (e.g., proliferative, early secretory, mid-secretory) as the
- This step generates a new, corrected expression matrix where the variance attributable to the menstrual cycle has been statistically removed.
Step 3: Differential Expression Analysis
- Perform your standard case versus control differential expression analysis on the cycle-corrected data using the
limmapackage. - For comparison and validation, also run the analysis on the uncorrected data.
- Compare the results. The corrected analysis should yield a higher number of true, pathology-related differentially expressed genes (DEGs) with greater statistical significance.
Validation: This method has been shown to recover significantly more candidate genes than analyses stratified by menstrual cycle phase, thereby increasing statistical power [1].
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials and Tools for Managing Menstrual Cycle Confounding
| Item / Reagent | Function / Application | Key Considerations |
|---|---|---|
| Human DiscoveryMAP (Myriad RBM) | Multiplex immunoassay panel for measuring 171+ serum proteins and small molecules. | Useful for broadly profiling analytes affected by hormonal status; provides a wide lens. [2] |
limma R Package |
Statistical package for analysis of gene expression data, particularly microarrays. | Contains critical functions for normalization, batch effect correction (removeBatchEffect), and differential expression. [1] |
edgeR R Package |
Statistical package for analysis of RNA-Seq data. | Used for low-count filtering and normalization of sequencing data prior to cycle effect correction. [1] |
| Fertility Monitors (e.g., ClearBlue Easy) | At-home urine test kits to track luteinizing hormone (LH) and estrogen metabolites. | Enables precise, biologically-relevant timing of sample collection relative to ovulation, superior to counting days. [3] |
Linear Models (via limma or other stats software) |
Statistical framework for correcting known batch effects. | The preferred method for statistically removing the menstrual cycle effect from data while preserving the signal of interest. [1] |
Visualizing the Solution: A Workflow for Robust Biomarker Discovery
The following diagram illustrates a side-by-side comparison of the problematic standard approach versus the recommended robust workflow for handling menstrual cycle confounding.
Troubleshooting Guides
Guide 1: Resolving Low Biomarker Discovery Yield
Problem: Your transcriptomic or metabolomic analysis is yielding an unexpectedly low number of statistically significant differentially expressed genes (DEGs) or metabolites when comparing case and control groups.
Diagnosis: This is a classic symptom of menstrual cycle phase effect masking true biological signals. The profound variation in gene expression and metabolite levels across the cycle can obscure disorder-related differences if not properly controlled.
Solution:
- Statistical Correction: Apply a batch effect removal method to your gene expression or metabolomic data, specifying the menstrual cycle phase as the batch to be removed. Use the
removeBatchEffectfunction from thelimmaR package (v.3.30.13 or higher), ensuring the design matrix preserves the case-versus-control group differences [1]. - Re-analyze Data: Re-run your differential expression analysis on the corrected data. Studies implementing this correction have discovered 44.2% more genes on average that were previously masked by cycle progression [1].
Guide 2: Addressing Inconsistent Biomarker Validation
Problem: Biomarkers identified in your research fail to validate in subsequent studies or show poor overlap with other published findings.
Diagnosis: Inconsistent or unregistered menstrual cycle phases at sample collection introduce a major source of variability, reducing the reproducibility of biomarker signatures across studies [1].
Solution:
- Audit Existing Data: Review the meta-data for your samples and those from studies you are comparing against. Determine if the menstrual cycle phase was recorded and if the proportion of samples from each phase is balanced between case and control groups (e.g., using Fisher's exact test) [1].
- Standardize Future Collection: Implement and document a standardized protocol for timing sample collection based on a specific cycle phase (e.g., mid-secretory phase for receptivity studies) or use statistical correction as in Guide 1.
Frequently Asked Questions (FAQs)
FAQ 1: How prevalent is the problem of unregistered menstrual cycle phases in endometrial research?
A systematic review of 35 endometrial transcriptomic studies found that 31.43% did not register the menstrual cycle phase at the time of biopsy collection [1]. This indicates that nearly one in three studies overlooks a major confounding variable, potentially compromising their findings.
FAQ 2: What is the quantitative impact of correcting for menstrual cycle phase on biomarker discovery?
Correcting for menstrual cycle bias significantly increases statistical power. One analysis of 12 studies showed that after correction, an average of 44.2% more candidate genes were identified [1]. For example, this method revealed 544 novel candidate genes for eutopic endometriosis and 158 for ectopic ovarian endometriosis that were previously masked [1].
FAQ 3: Beyond reproductive tissues, do menstrual cycle phases affect other biomarkers?
Yes, the effect is widespread. Cardiometabolic biomarkers show significant rhythmicity [3]. For instance, the percentage of women with cholesterol levels ≥200 mg/dL (indicating a need for therapy) is nearly twice as high in the follicular phase compared to the luteal phase (14.3% vs. 7.9%) [3]. High-sensitivity C-reactive protein (hsCRP), a marker of cardiovascular risk, also fluctuates, with nearly twice as many women classified as high risk (>3 mg/L) during menses [3].
FAQ 4: What are the specific metabolic patterns observed across a healthy menstrual cycle?
Metabolomic studies reveal consistent patterns. In the luteal phase, there are significant decreases in many plasma amino acids, biogenic amines, and phospholipids, possibly indicating an anabolic state [6]. For example, 37 amino acids and derivatives showed a significant decrease in the luteal versus menstrual phase contrast after multiple-testing correction [6]. Conversely, Vitamin D (25-OH vitamin D) and pyridoxic acid levels are often higher in the menstrual phase [6].
Quantitative Data on Prevalence and Impact
Table 1: Impact of Menstrual Cycle Phase Correction on Biomarker Discovery
| Pathology Studied | Increase in Discovered Genes After Correction | Specific Novel Candidates Revealed |
|---|---|---|
| Eutopic Endometriosis | Significant increase | 544 novel candidate genes [1] |
| Ectopic Ovarian Endometriosis | Significant increase | 158 novel candidate genes [1] |
| Recurrent Implantation Failure (RIF) | Significant increase | 27 novel candidate genes [1] |
| Multiple Studies (Average) | 44.2% more genes on average [1] | --- |
Table 2: Prevalence of Phase Oversight and Biomarker Variability
| Aspect | Finding | Source |
|---|---|---|
| Unregistered Cycle Phase | 31.43% of transcriptomic studies (11 of 35) [1] | [1] |
| Cholesterol Variability (≥200 mg/dL) | Follicular: 14.3%, Luteal: 7.9% [3] | [3] |
| hsCRP Variability (>3 mg/L) | Menses: 12.3%, Other Phases: 7.4% [3] | [3] |
| Metabolite Reduction in Luteal Phase | 39 amino acids and derivatives, 18 lipid species [6] | [6] |
Experimental Protocols for Bias Correction
Protocol 1: Menstrual Cycle Effect Correction in Transcriptomic Data
This protocol uses linear models to remove the variation in gene expression data attributable to the menstrual cycle.
- Data Pre-processing: Download raw data from GEO. Normalize between samples using quantile normalization (
limmaR package). Annotate probesets to gene symbols (biomaRtR package) [1]. - Exploratory Analysis: Perform a Principal Component Analysis (PCA) to visualize the menstrual cycle effect (
ggplot2R package). Test for imbalance in phase distribution between case and control groups using Fisher's exact test [1]. - Bias Correction: Use the
removeBatchEffectfunction (limmaR package). Specify thebatchparameter as the variable containing the menstrual cycle phase for each sample. Define thedesignparameter as a model matrix preserving the condition of interest (e.g., ~CaseStatus) [1]. - Differential Expression Analysis: Perform case versus control differential expression analysis on the corrected data using the
lmFitandeBayesfunctions (limmaR package). Genes with an FDR (False Discovery Rate) < 0.05 are considered significant [1].
Protocol 2: Five-Phase Metabolic Profiling Across the Menstrual Cycle
This protocol outlines the rigorous sampling and analysis for capturing metabolic rhythmicity.
- Participant Selection & Sample Collection: Enroll healthy, premenopausal, naturally cycling women. Collect biofluids (plasma, urine, serum) at five precisely timed phases: Menstrual, Follicular, periOvulatory, Luteal, and Pre-menstrual. Use serum hormones, urinary LH, and self-reported timing for accurate phase classification [6].
- Metabolomic & Lipidomic Analysis: Analyze plasma and urine using LC-MS and GC-MS platforms. Perform targeted profiling for amino acids, biogenic amines, lipids (phospholipids, acylcarnitines), organic acids, and vitamins [6].
- Data Analysis & Rhythmicity Assessment: For each biochemical species, compare calculated phase means. Test phase-phase contrasts (e.g., Luteal vs. Follicular - L-F) for statistical significance (p < 0.05). Control for multiple testing using a False Discovery Rate (FDR) threshold (e.g., q < 0.20) to identify metabolites with significant rhythmicity [6].
Signaling Pathways and Experimental Workflows
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials and Tools for Menstrual Cycle-Aware Research
| Item / Resource | Function / Application | Key Details |
|---|---|---|
limma R Package |
Performs differential expression analysis and batch effect correction. | Used with removeBatchEffect function to statistically remove menstrual cycle phase variation while preserving disease-related signals [1]. |
| Fertility Monitors | Precisely timing biological sample collection to specific menstrual cycle phases. | Tracks urinary LH and estrogen metabolites to detect the LH surge and predicted ovulation, enabling phase-specific sampling [3]. |
| LC-MS / GC-MS Platforms | Comprehensive metabolomic and lipidomic profiling of biofluids. | Used to quantify hundreds of metabolites (amino acids, lipids, vitamins) and reveal their rhythmic patterns across the cycle [6]. |
| ANOVA with FDR Correction | Statistical method for identifying rhythmic metabolites. | Tests for significant differences in metabolite levels across multiple cycle phases, with FDR control to account for multiple comparisons [6]. |
In endometrial research, the profound transcriptomic changes driven by the menstrual cycle are not just a subject of study but a significant source of confounding variation. Failure to account for this dynamic biological context can mask true disease-specific signatures, leading to non-reproducible results and hindering biomarker discovery. This technical support guide, framed within the thesis of correcting menstrual cycle bias, provides actionable protocols and FAQs to help researchers design robust experiments and unmask genuine molecular signals associated with uterine pathologies.
Frequently Asked Questions (FAQs) & Troubleshooting Guides
How significant is the menstrual cycle as a confounding variable?
Problem: Inconsistent findings between transcriptomic studies of endometrial disorders. Solution: The menstrual cycle is a major confounding factor. A systematic review found that 31.4% of transcriptomic studies did not even register the menstrual cycle phase of their samples. When cycle bias is statistically corrected, studies identify dramatically more differentially expressed genes (DEGs)—on average, 44.2% more genes for conditions like endometriosis and recurrent implantation failure (RIF) [1] [7].
Troubleshooting Guide: If your gene list is smaller than expected or lacks known pathways, check for unbalanced cycle phase distribution between case and control groups.
How can I correct for menstrual cycle bias in my experimental design?
Problem: Designing a study to isolate pathology-specific signals from cycle-driven changes. Solution: Adopt a stratified sampling and computational correction approach.
- Step 1 - Precise Timing: Date samples using the LH surge or a molecular staging model rather than last menstrual period (LMP) or histology alone for greater accuracy [8] [9].
- Step 2 - Phase Balancing: Ensure case and control groups are balanced for the proportion of samples from each cycle phase (e.g., early secretory, mid-secretory) [1].
- Step 3 - Computational Correction: Use linear models (e.g., the
removeBatchEffectfunction in thelimmaR package) to remove the variation in gene expression data explained by the cycle phase, while preserving the case vs. control differences [1].
Why does single-cell resolution improve the study of endometrial dynamics?
Problem: Bulk RNA sequencing averages expression across all cell types, obscuring critical cell-specific changes. Solution: Single-cell RNA sequencing (scRNA-seq) resolves the endometrium's complex cellular architecture. A 2025 study profiling over 220,000 cells across the window of implantation (WOI) uncovered a two-stage decidualization process in stromal cells and a gradual transition in luminal epithelial cells, dynamics that are invisible in bulk data [10]. In RIF patients, scRNA-seq can stratify endometrial deficiencies into distinct classes based on epithelial receptivity gene sets [10].
Troubleshooting Guide: If bulk RNA-seq yields a "muddy" transcriptome with conflicting pathways, consider scRNA-seq to pinpoint the specific cell type driving the signal.
What are the key quantitative changes in transcriptomics across the cycle?
The table below summarizes the dynamic expression of key functional gene groups across the menstrual cycle phases, based on transcriptomic studies [11].
| Menstrual Phase | Key Upregulated Biological Processes | Representative Genes |
|---|---|---|
| Menstrual | Inflammation, Tissue breakdown, Apoptosis, DNA repair | NCR3, Wnt5a, Wnt7a, MMP1, MMP3, MMP10, F2R (PAR-1), LOX |
| Proliferative | Cell proliferation, Tissue remodeling, Angiogenesis | CCL18, MT2A, MMP26, HOXA10, HOXA11, CXCR4, PECAM1 |
| Secretory | Immune regulation, Decidualization, Receptivity | PAEP, GPX3, CXCL14, DKK1, IL-15, FOXO1 |
What methodological considerations are crucial for spatial transcriptomics?
Problem: Understanding the spatial context of gene expression in endometrial tissue. Solution: Spatial transcriptomics (ST) preserves the architectural context of cells. A recent ST study of RIF and normal endometrium generated an average of 3,156 genes per high-quality spot, identifying seven distinct cellular niches with specific gene expression profiles [12]. Successful ST requires:
- High-Quality RNA: Use fresh-frozen tissues with an RNA Integrity Number (RIN) > 7.
- Optimized Permeabilization: Determine optimal tissue permeabilization time to maximize mRNA capture.
- Integration with scRNA-seq: Use deconvolution tools (e.g., CARD) to infer the cellular composition within each spatially barcoded spot [12].
Experimental Protocols
Protocol 1: Correcting Menstrual Cycle Bias in Bulk Transcriptomic Data
This protocol uses linear models to statistically remove the effect of the menstrual cycle, as validated in [1].
Materials: Raw gene expression data (microarray or RNA-seq), sample metadata including precise cycle phase or day.
Procedure:
- Pre-processing: Normalize raw data (e.g., using
limmafor microarrays oredgeRfor RNA-seq) and perform exploratory PCA to visualize cycle-driven clustering. - Batch Definition: Define the "batch" covariate as the menstrual cycle phase (e.g., proliferative, early-secretory, mid-secretory) or a continuous model time from a molecular staging model [8].
- Model Fitting: Use the
removeBatchEffectfunction from thelimmaR package, specifying the cycle phase as the batch to remove and the case/control status as the design variable to preserve. - Differential Expression: Perform standard differential expression analysis (e.g., with
limma) on the corrected data. - Validation: Compare the number and biological relevance of DEGs before and after correction. The power of this method exceeds analyzing each cycle phase independently [1].
Protocol 2: Generating a Single-Cell Transcriptomic Atlas of the Window of Implantation
This protocol is adapted from a high-resolution study of the luteal phase [10].
Materials: Endometrial biopsies timed via serial blood LH tests (e.g., LH+3, +5, +7, +9, +11), enzymatic digestion cocktail for tissue dissociation, 10X Chromium controller, sequencer (e.g., Illumina NovaSeq).
Procedure:
- Sample Collection & Dissociation: Collect endometrial aspirates or biopsies. Dissociate tissue into a single-cell suspension using enzymatic digestion (e.g., collagenase).
- Single-Cell Library Preparation: Load cells onto a 10X Chromium controller to generate single-cell Gel Bead-In-Emulsions (GEMs). Perform reverse transcription, cDNA amplification, and library construction per 10X Visium protocol.
- Sequencing & Primary Analysis: Sequence libraries and use
Cell Rangerto align reads to the genome (e.g., GRCh38), detect cells, and generate count matrices. - Quality Control & Clustering: Using
SeuratorScanpy, filter out low-quality cells (high mitochondrial percentage, low gene counts). Normalize data, identify highly variable genes, perform PCA, and cluster cells. Annotate clusters using canonical markers (e.g.,EPCAMfor epithelial,PDPNfor stromal,PTPRCfor immune). - Trajectory & Dynamics Analysis: Use RNA velocity or pseudotime tools (e.g.,
ScVelo,StemVAE) to model cellular transitions and identify dynamic gene expression patterns across the collected time points.
| Reagent / Resource | Function / Application | Key Considerations |
|---|---|---|
| limma R Package | Statistical models for removing batch effects (e.g., cycle phase) from transcriptomic data. | The removeBatchEffect function is recommended for known biases like the menstrual cycle [1]. |
| 10X Visium Platform | Spatial transcriptomics for capturing gene expression within tissue architecture. | Requires fresh-frozen tissue and optimization of permeabilization time [12]. |
| Seurat / Scanpy | Computational toolkits for single-cell RNA-seq data analysis, including clustering, visualization, and differential expression. | Essential for annotating cell types and analyzing cell-type-specific responses [12] [10]. |
| CARD | Deconvolution tool to estimate cell type proportions in spatial transcriptomics spots using a reference scRNA-seq dataset. | Crucial for interpreting cellular heterogeneity within spatial data [12]. |
| Endometrial Receptivity Array (ERA) | Diagnostic tool using a transcriptomic signature to pinpoint the personal window of implantation. | More accurate and reproducible than histologic dating for defining the receptive phase [13] [9]. |
| Molecular Staging Model | A computational model that assigns a precise "model time" to any endometrial sample based on global gene expression. | Overcomes variability in cycle length and provides a continuous scale for sample alignment [8]. |
Visualizing Complex Workflows and Relationships
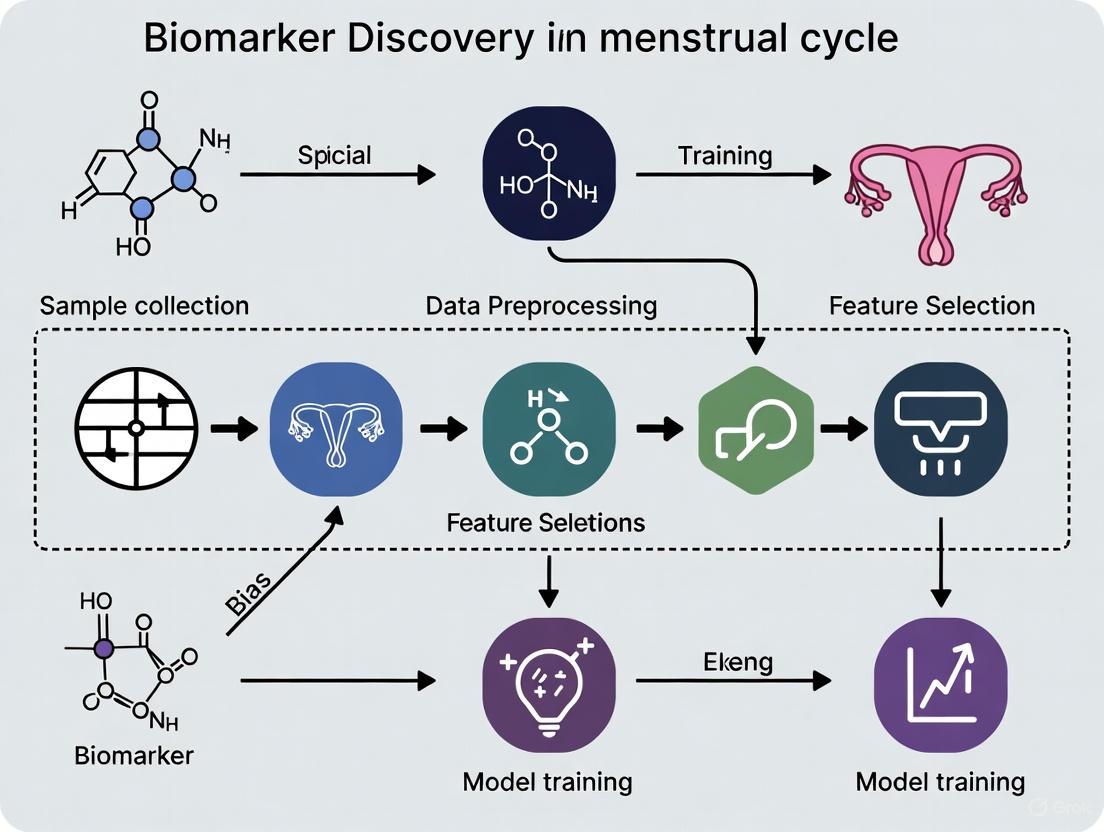
Diagram: Experimental Workflow for Unmasking Endometrial Biomarkers
This diagram outlines the key steps for a transcriptomic study designed to correct for menstrual cycle bias, leading to more robust biomarker discovery.
Diagram: Transcriptomic Changes in the Window of Implantation
This diagram summarizes the key cellular and molecular dynamics in the endometrium during the critical window of implantation, as revealed by recent single-cell studies [10].
Troubleshooting Guides
Guide 1: Resolving Poor Reproducibility in Endometrial Biomarker Studies
Problem: Reported biomarkers for uterine disorders (e.g., endometriosis, RIF) show poor overlap between studies and fail validation.
- Potential Cause 1: Menstrual cycle phase is masking true disorder-related gene expression.
- Solution: Re-analyze gene expression data using linear models to remove menstrual cycle bias before differential expression analysis. This can unmask 44.2% more significant genes on average [1].
- Potential Cause 2: Study design does not account for or balance sample collection across menstrual cycle phases.
- Solution: Record the menstrual cycle phase for all endometrial biopsies. In subsequent analyses, use the
removeBatchEffectfunction (limma R package) specifying the menstrual cycle phase as the batch to remove, while preserving the case vs. control group differences [1].
- Solution: Record the menstrual cycle phase for all endometrial biopsies. In subsequent analyses, use the
Guide 2: Addressing Inconsistent Cardiometabolic Biomarker Readings in Premenopausal Women
Problem: Measurements for biomarkers like cholesterol or C-reactive protein in premenopausal women are highly variable, leading to inconsistent risk classification.
- Potential Cause: Biomarker levels fluctuate significantly across the menstrual cycle due to hormonal changes.
- Solution: Standardize the timing of blood collection to a specific menstrual cycle phase for all participants in a cohort. Note that the follicular phase can show nearly double the number of women with clinically high cholesterol (≥200 mg/dL) compared to the luteal phase (14.3% vs. 7.9%) [3]. Failing to account for this can misclassify CVD risk.
Frequently Asked Questions (FAQs)
Q1: Why is it critical to account for the menstrual cycle in women's health research? The menstrual cycle causes significant natural variation in many physiological processes and biomarkers. This variation is an important source of bias and noise. If not controlled, it can obscure true signals related to diseases or treatments, leading to false negatives, non-reproducible findings, and a fundamental misunderstanding of female biology [14] [3]. For example, the belief that mood swings are directly caused by the menstrual cycle in healthy women has been challenged by research pointing to poor sleep as the primary culprit [15].
Q2: What are the historical roots of this bias? Two major factors created this bias:
- Protective Exclusion: Following the thalidomide scandal, a 1977 FDA guideline recommended excluding women of childbearing potential from clinical research to protect unborn children [16].
- Simplification and Cost: The hormonal variability of the menstrual cycle was viewed as a complication that would increase the cost and complexity of studies. This led to the erroneous assumption that male-only studies were sufficient, and results could be extrapolated to women [16].
Q3: What have been the consequences for women's health? The consequences are severe and ongoing:
- Misdiagnosis and Delayed Diagnosis: Symptoms for conditions like heart disease in women are often less recognized, leading to diagnoses 7-10 years later than in men [16].
- Drug Safety Issues: Eight out of ten drugs withdrawn from the U.S. market between 1997 and 2000 were due to side effects occurring mainly or exclusively in women [16].
- Underfunding and Underresearch: Women's health has been treated as a niche area. In the UK, less than 2.5% of publicly-funded research was dedicated to reproductive health, despite one in three women suffering from a related issue [16].
- Stigmatization and Poor Care: Menstrual stigma leads to secrecy, normalisation of severe symptoms, and reluctance to seek healthcare, further hindering progress and quality of life [17].
Q4: What is a key methodological improvement for transcriptomic studies of the endometrium? Instead of analyzing data within single menstrual phases, use a full-cycle study design and apply a menstrual cycle bias correction method. One study discovered 544 novel candidate genes for endometriosis and 27 genes for recurrent implantation failure only after applying this correction, which increased the statistical power of the analysis [1].
Q5: How can I account for cycle variability if my participants have irregular cycles? Rely on empirical biomarkers of cycle physiology rather than calendar-based estimates. Use fertility monitors to track hormone metabolites (e.g., luteinizing hormone) to pinpoint biologically relevant events like ovulation. Cycle length alone is an inadequate biomarker for ovulation or hormone production [14] [3].
Table 1: Impact of Menstrual Cycle Phase on Cardiometabolic Biomarker Classification
This table summarizes how failure to account for menstrual cycle phase can lead to misclassification of disease risk in premenopausal women [3].
| Biomarker | Risk Threshold | Menstrual Cycle Phase | % of Women Classified as High Risk | Clinical Implication of Misclassification |
|---|---|---|---|---|
| Total Cholesterol | ≥200 mg/dL | Follicular Phase | 14.3% | Overestimation of CVD risk and potential for unnecessary treatment |
| Luteal Phase | 7.9% | |||
| High-sensitivity C-Reactive Protein (hsCRP) | >3 mg/L | Menses | 12.3% | Inconsistent CVD risk stratification across the cycle |
| Other Phases | 7.4% |
Table 2: Key Reagent Solutions for Menstrual Cycle-Biased Biomarker Discovery
This table lists essential materials and tools for designing robust studies that account for menstrual cycle effects.
| Research Reagent / Tool | Function in Experimental Design | Key Consideration |
|---|---|---|
| Fertility Monitors (e.g., ClearBlue Easy) | Tracks urinary luteinizing hormone (LH) and estrogen metabolites to objectively identify the LH surge and ovulation for precise cycle phase timing [3]. | Prefer over calendar counting for accurate phase determination, especially in women with variable cycle lengths. |
Linear Models with Batch Effect Correction (e.g., removeBatchEffect in limma R package) |
A statistical method to computationally remove the variation in data (e.g., gene expression) caused by menstrual cycle phase, thereby unmasking variation due to the pathology of interest [1]. | The design matrix must be correctly specified to preserve the case vs. control group differences while removing the cycle "batch" effect. |
| Menstrual Blood Collection Device (e.g., Prototype: FloSync) | A standardized, clinical-grade menstrual cup with a built-in filtration system for non-invasive collection of menstrual fluid, which is a rich source of diagnostic biomarkers [18]. | Enables longitudinal sampling in a non-clinical setting and provides a novel biofluid for biomarker discovery. |
| Validated PROMs/ePROs (Patient-Reported Outcome Measures) | Captures subjective data on symptoms, mood, and quality of life. When paired with objective sleep and activity data from wearables, it helps disentangle cycle effects from other factors like poor sleep [15] [19]. | Digital collection (ePRO) improves adherence and data quality. Correlation with objective measures strengthens findings. |
Experimental Protocols & Workflows
Detailed Methodology: Correcting Menstrual Cycle Bias in Transcriptomic Data
Objective: To identify differentially expressed genes (DEGs) for a uterine disorder (e.g., endometriosis) while controlling for the confounding effect of the menstrual cycle.
Workflow Overview:
Step-by-Step Protocol:
- Data Pre-processing:
- Download raw gene expression data (microarray or RNA-Seq) from public repositories like GEO.
- For microarray data, use the
affy(for Affymetrix) orlimma(for Agilent/Illumina) R packages for background correction and normalization (e.g., quantile normalization) [1]. - For RNA-Seq data, use the
edgeRR package for low-count filtering and normalization [1]. - Annotate probesets to official gene symbols using a package like
biomaRt.
Exploratory Analysis:
- Perform Principal Component Analysis (PCA) using the pre-processed data.
- Color the PCA plot by the recorded menstrual cycle phase of each sample. This visualization often reveals a strong clustering of samples by cycle phase, indicating a significant batch effect that must be corrected [1].
Menstrual Cycle Bias Correction:
- Use the
removeBatchEffect()function from thelimmaR package (v.3.30.13 or higher). - In the function call, specify the
batchparameter as the factor variable representing the menstrual cycle phase for each sample. - The
designparameter should be a model matrix defining the biological condition you wish to preserve (e.g., ~ Group, where Group is "Case" or "Control"). - This function returns a corrected matrix of gene expression values, with the variation due to the menstrual cycle removed [1].
- Use the
Differential Expression Analysis:
- Perform standard case vs. control differential expression analysis on the bias-corrected data using the
limmapackage (for microarrays or RNA-Seq). - Apply a False Discovery Rate (FDR) correction (e.g., FDR < 0.05) to identify statistically significant DEGs.
- Validation: Compare the number and identity of DEGs obtained from the corrected analysis with those from an analysis of the raw, uncorrected data. The corrected analysis is expected to yield a significantly higher number of true, pathology-related DEGs [1].
- Perform standard case vs. control differential expression analysis on the bias-corrected data using the
A Practical Framework: Statistical and Experimental Designs to Correct for Cycle Bias
FAQs: Addressing Key Challenges in Biomarker Research
What is the most common source of irreproducibility in endometrial biomarker studies?
The most significant source of irreproducibility in endometrial biomarker studies is failure to account for menstrual cycle effects. Molecular changes across the menstrual cycle can mask true disease-related signals.
- Substantial Impact: When menstrual cycle bias is corrected using linear models, researchers identify an average of 44.2% more significant genes associated with uterine disorders [1].
- Prevalence of the Problem: A systematic review found that 31.43% of endometrial studies did not register the menstrual cycle phase of collected samples [1].
- Statistical Evidence: In studies examining the same endometrial pathology, minimal overlap exists in reported differentially expressed genes. For example, across four endometriosis studies, only six genes overlapped between at least two studies out of 1,307 candidate genes identified [20].
Table 1: Effect of Menstrual Cycle Correction on Biomarker Discovery
| Condition Studied | Additional Genes Identified After Cycle Correction | Statistical Method |
|---|---|---|
| Eutopic Endometriosis | 544 novel candidate genes | Linear models (removeBatchEffect) |
| Ovarian Endometriosis | 158 novel candidate genes | Linear models (removeBatchEffect) |
| Recurrent Implantation Failure | 27 novel candidate genes | Linear models (removeBatchEffect) |
How can I statistically correct for menstrual cycle effects in my biomarker data?
The most effective method uses linear models to remove menstrual cycle variation while preserving disease-related signals.
Protocol for Menstrual Cycle Bias Correction [1]:
- Specify menstrual cycle phase of each endometrial biopsy collection as the batch effect to remove
- Define a design matrix that preserves the condition differences (case versus control samples)
- Apply the removeBatchEffect function from the limma R package (v.3.30.13 or higher)
- Perform differential expression analysis on the corrected data using the same package
Key Advantage: This method increases statistical power by retrieving more candidate genes than per-phase independent analyses, as it uses the entire dataset while controlling for cycle effects [1].
What are the critical pre-analytical factors that compromise biomarker data quality?
Pre-analytical errors account for approximately 70% of all laboratory diagnostic mistakes [21]. The most critical factors are:
Table 2: Common Laboratory Issues Impacting Biomarker Data Quality
| Issue Category | Specific Problems | Impact on Data |
|---|---|---|
| Temperature Regulation | Improper flash freezing, inconsistent thawing, cold chain breaks | Biomarker degradation (proteins, nucleic acids) |
| Sample Preparation | Variable extraction methods, non-validated reagents, operator-dependent techniques | Introduces batch effects and variability |
| Contamination | Environmental contaminants, cross-sample transfer, reagent impurities | False positives, skewed biomarker profiles |
| Human Factors | Cognitive fatigue (up to 70% function decline with sustained focus), procedural complexity | Increased error rates in analysis and interpretation |
What validation metrics are essential for assessing biomarker performance?
Biomarker validation requires multiple performance metrics to establish clinical utility [22]:
Table 3: Essential Biomarker Performance Metrics
| Metric | Description | Interpretation |
|---|---|---|
| Sensitivity | Proportion of true cases that test positive | Ideal: >80% for diagnostic biomarkers |
| Specificity | Proportion of true controls that test negative | Ideal: >80% for diagnostic biomarkers |
| ROC AUC | Area Under Receiver Operating Characteristic Curve | 0.5 = coin flip, 0.7-0.8 = acceptable, 0.9-1.0 = excellent |
| Positive Predictive Value | Proportion of test positive patients who have the disease | Highly dependent on disease prevalence |
| Calibration | How well biomarker estimates match observed risk | Critical for prognostic biomarkers |
How do prognostic and predictive biomarkers differ in their identification?
These biomarker types require distinct study designs and statistical approaches [22]:
Prognostic Biomarkers:
- Study Design: Properly conducted retrospective studies using biospecimens from cohorts representing target population
- Statistical Test: Main effect test of association between biomarker and outcome
- Example: STK11 mutation associated with poorer outcome in non-squamous NSCLC
Predictive Biomarkers:
- Study Design: Secondary analyses using data from randomized clinical trials
- Statistical Test: Interaction test between treatment and biomarker
- Example: EGFR mutation status in IPASS study - interaction P<0.001 for gefitinib vs. carboplatin+paclitaxel
Troubleshooting Guides
Problem: Inconsistent Biomarker Results Across Studies
Solution: Implement rigorous study design and data standardization
- Define precise objectives and scope with detailed inclusion/exclusion criteria [23]
- Apply standardized data curation including value range checks, unit consistency, and format transformation to standards like OMOP or CDISC [23]
- Use molecular dating methods for endometrial samples to improve cycle timing precision [20]
- Control for multiple comparisons with False Discovery Rate (FDR) measures, especially for high-dimensional data [22]
Problem: Low Statistical Power Despite Adequate Sample Size
Solution: Address hidden sources of variation and confounding
- Account for major sources of variation like menstrual cycle timing in principal component analysis [20]
- Implement randomization and blinding during biomarker data generation to prevent bias [22]
- Use pre-planned analysis protocols written before data receipt to avoid data-influenced analyses [22]
- Apply variable selection methods like shrinkage to minimize overfitting when combining multiple biomarkers [22]
Problem: Failed Translation of Biomarkers to Clinical Settings
Solution: Enhance clinical validation and utility assessment
- Conduct both analytical and clinical validation - analytical validation establishes performance metrics, while clinical validation demonstrates link to clinical outcomes [24]
- Assess added value over existing clinical markers through comparative evaluations [23]
- Consider implementation factors early: cost-effectiveness, workflow integration, and regulatory compliance [25]
- Evaluate real-world clinical relevance through continued post-implementation surveillance [24]
Experimental Protocols
Materials:
- Endometrial biopsy RNA samples with confirmed menstrual cycle phase
- R statistical environment with limma package (v.3.30.13 or higher)
- Clinical metadata including case/control status
Procedure:
- Pre-process raw gene expression data using platform-specific methods
- Perform exploratory analysis to detect batch effects
- Apply
removeBatchEffectfunction specifying:- Menstrual cycle phase as batch to remove
- Design matrix preserving case versus control differences
- Conduct differential expression analysis on corrected data using
limma - Compare results with and without cycle correction to assess improvement
Three Integration Strategies:
- Early Integration: Extract common features from multiple data modalities using methods like Canonical Correlation Analysis (CCA)
- Intermediate Integration: Join data sources during model building using multimodal neural networks or kernel methods
- Late Integration: Build separate models for each data type and combine predictions via stacked generalization
Workflow Visualization
Workflow for Robust Endometrial Biomarker Discovery
Impact of Menstrual Cycle Bias Correction
The Scientist's Toolkit: Essential Research Reagent Solutions
Table 4: Key Reagents and Platforms for Biomarker Discovery
| Tool Category | Specific Examples | Function in Workflow |
|---|---|---|
| Automated Homogenization | Omni LH 96 automated homogenizer | Standardizes sample disruption, reduces contamination risk by up to 40% [21] |
| Bioinformatics Platforms | Polly platform (Elucidata), limma R package | Data harmonization, batch effect correction, differential expression analysis [1] [25] |
| Multi-Omics Integration | Canonical Correlation Analysis, multimodal neural networks | Combines genomics, transcriptomics, proteomics for comprehensive biomarker panels [23] |
| Quality Control Tools | fastQC (NGS), arrayQualityMetrics (microarrays), Normalyzer (proteomics) | Data type-specific quality assessment and normalization [23] |
Why is accounting for the menstrual cycle essential in endometrial research?
The endometrium is a uniquely dynamic tissue that undergoes profound molecular changes throughout the menstrual cycle in response to hormonal fluctuations. Research has demonstrated that menstrual cycle timing is typically the dominant source of variation in endometrial omics data, often captured in the first principal component in dimensionality reduction analyses. [20] This variation presents a substantial confounding effect that can completely obscure true biological signals in biomarker discovery studies.
Concerningly, a systematic review of published endometrial datasets found that among 35 case-control studies, 11 studies (31%) did not record any menstrual cycle phase information at the time of biopsy, and 13 studies (37%) collected all samples in either the proliferative or secretory phase with no further subdivision. [20] This methodological inconsistency contributes significantly to the reproducibility crisis in endometrial research, where studies investigating the same endometrial pathology show minimal overlap in identified candidate genes. [20]
Foundational Concepts: Understanding Menstrual Cycle Variability
FAQ: What are the key phases of the menstrual cycle and their molecular significance?
The menstrual cycle is divided into three main phases characterized by distinct hormonal profiles and endometrial changes [26]:
- Early Follicular Phase: Begins with menses onset, characterized by low progesterone and gradually increasing estradiol levels.
- Pre-ovulatory Phase: Estradiol levels peak, triggering ovulation.
- Mid-Luteal Phase: Progesterone levels reach their highest concentration.
Each phase exhibits unique gene expression patterns, with thousands of genes showing rapid changes over approximate 24-hour windows at multiple time points in the cycle. [20] This natural biological variation must be accounted for in statistical models to distinguish true biomarker signals from cycle-induced noise.
FAQ: How does demographic factors influence menstrual cycle characteristics?
Table 1: Demographic Factors Influencing Menstrual Cycle Characteristics
| Factor | Effect on Cycle Length | Effect on Cycle Variability | Data Source |
|---|---|---|---|
| Age <20 | 1.6 days longer vs. 35-39 age group | 46% higher variability vs. 35-39 age group | [27] |
| Age 45-49 | 0.3 days shorter vs. 35-39 age group | Comparable to younger groups | [27] |
| Age >50 | 2.0 days longer vs. 35-39 age group | 200% higher variability vs. 35-39 age group | [27] |
| Asian Ethnicity | 1.6 days longer vs. white participants | Higher variability | [27] |
| Hispanic Ethnicity | 0.7 days longer vs. white participants | Higher variability | [27] |
| Obesity (Class 3) | 1.5 days longer vs. healthy BMI | Higher variability | [27] |
Experimental Design Considerations
Best Practices for Sample Collection and Cycle Dating
How should I time sample collection to minimize cycle-related confounding?
The gold standard approach involves [28]:
- Repeated measures designs that treat the menstrual cycle as a within-person process
- Daily or multi-daily assessments (ecological momentary assessments) for outcomes
- At least three observations per person across one cycle as a minimal standard for estimating within-person effects
- Three or more observations across two cycles for reliable estimation of between-person differences in within-person changes
What methods are available for accurate cycle phase determination?
Table 2: Methodologies for Menstrual Cycle Phase Determination
| Method | Precision | Advantages | Limitations | Suitable for |
|---|---|---|---|---|
| Histological Dating (Noyes Criteria) | Low | Traditional standard, widely accepted | Subjective, limited precision | Initial phase classification |
| Hormone Level Measurement | Medium | Direct hormone quantification | Requires blood draws, costly | Cycle phase confirmation |
| Molecular-based Dating | High | Objective, high precision | Computational complexity, emerging method | Biomarker discovery studies |
| Peak Day of Mucus Discharge | Medium | Non-invasive, self-administered | Requires patient training | Natural cycle studies |
Troubleshooting Guide: Common Sample Collection Errors
Problem: Inconsistent cycle phase classification across samples. Solution: Implement molecular-based dating methods that use gene expression patterns to precisely estimate menstrual cycle time for endometrial tissue samples. [20]
Problem: High within-group variability obscuring biomarker signals. Solution: Collect detailed demographic information including age, ethnicity, and BMI, as these factors significantly influence cycle characteristics. [27]
Problem: Inaccurate self-reported cycle phase information. Solution: Implement hormonal validation of cycle phase through serum or urine testing, particularly for studies focusing on specific cycle phases. [28]
Statistical Implementation of Linear Models for Cycle Correction
Step-by-Step Protocol: Implementing Cycle Correction in Omics Data
Phase 1: Data Preparation and Cycle Time Estimation
- Obtain molecular cycle time estimates using established gene expression signatures
- Validate cycle phase with hormonal measurements when possible
- Code cycle day and phases using standardized definitions [28]
Phase 2: Model Specification and Implementation
- Include cycle time as a covariate in linear models to account for systematic variation
- Consider interaction terms between cycle time and experimental conditions when biologically plausible
- Use multilevel modeling to account for within-person correlations in repeated measures designs [28]
Phase 3: Model Validation and Diagnostics
- Visualize residuals to check for remaining cycle-related patterns
- Compare model fit with and without cycle correction terms
- Validate findings in independent datasets when possible
Experimental Workflow Visualization
Diagram 1: Experimental workflow for menstrual cycle effect correction
Advanced Methodologies and Case Studies
Case Study: Endometrial Failure Risk (EFR) Signature Development
A 2024 study demonstrated the successful implementation of cycle correction in identifying biomarkers for endometrial failure. [29] The research team:
- Collected endometrial biopsies in the mid-secretory phase from 281 patients
- Measured expression of 404 genes with known cycle-related patterns
- Removed endometrial timing variation from gene expression data
- Stratified patients into poor (n=137) or good (n=49) endometrial prognosis groups
- Developed the EFR signature comprising 59 upregulated and 63 downregulated genes
The results showed dramatic differences in reproductive outcomes [29]:
- Pregnancy rates: 44.6% (poor prognosis) vs. 79.6% (good prognosis)
- Live birth rates: 25.6% (poor prognosis) vs. 77.6% (good prognosis)
- Clinical miscarriage: 22.2% (poor prognosis) vs. 2.6% (good prognosis)
This case study demonstrates how proper cycle correction can reveal biologically significant signatures that would otherwise be masked by cycle-related variation.
Statistical Model Relationships
Diagram 2: Statistical partitioning of variance in linear models
Research Reagent Solutions
Table 3: Essential Research Reagents and Resources for Menstrual Cycle Studies
| Reagent/Resource | Function/Purpose | Example Application | Technical Notes |
|---|---|---|---|
| Standardized Cycle Tracking System | Prospective daily monitoring of cycles and symptoms | Identifying precise cycle phases for sample timing | Carolina Premenstrual Assessment Scoring System (C-PASS) available [28] |
| Molecular Dating Gene Panel | Precise estimation of endometrial tissue cycle time | Correcting for cycle phase in omics studies | Typically includes 100+ cycle-responsive genes [20] |
| Hormone Assay Kits | Quantification of estradiol and progesterone | Validation of cycle phase determination | Requires serum or urine samples [28] |
| Standardized Biopsy Collection Kits | Consistent endometrial tissue sampling | Ensuring sample quality for omics analyses | Includes preservation solutions for different analyses |
| Cycle-Aware Statistical Packages | Implementation of linear models with cycle correction | Bioinformatics analysis of omics data | R/Bioconductor packages available |
Troubleshooting Advanced Scenarios
FAQ: How do I handle cycle effects in diverse patient populations?
Challenge: Menstrual cycle characteristics vary significantly by age, ethnicity, and BMI. [27] Solution: Include these demographic factors as covariates in your linear models and test for interaction effects between these factors and cycle time.
Challenge: Patients with gynecological conditions may exhibit altered cycle patterns. Solution: Consider condition-specific cycle correction approaches and validate findings in both affected and control populations.
FAQ: What are the limitations of linear models for cycle correction?
While linear models are powerful tools for removing menstrual cycle effects, researchers should be aware of several limitations:
- Non-linear relationships between cycle time and molecular measures may require more complex modeling approaches
- Interaction effects between cycle phase and experimental conditions may complicate interpretation
- Insufficient sample size across cycle phases can limit model accuracy
- Population-specific effects may necessitate validation across diverse cohorts
Validation and Quality Control Measures
Essential Steps for Validating Cycle Correction
- Principal Component Analysis (PCA) Visualization: Examine whether cycle-related variation diminishes in corrected data
- Negative Control Analysis: Verify that known cycle-responsive genes are no longer significantly associated with cycle time after correction
- Positive Control Analysis: Ensure that biological signals of interest remain significant after cycle correction
- Independent Cohort Validation: Replicate findings in separate populations with different cycle characteristics
By implementing these comprehensive methodologies for leveraging linear models to remove menstrual cycle effects, researchers can significantly improve the reproducibility and reliability of endometrial biomarker discovery research.
In the field of endometriosis research, transcriptomic approaches are increasingly used to identify candidate endometrial biomarkers. However, a significant confounding variable has been largely overlooked: the profound effect of menstrual cycle progression on endometrial gene expression. This technical challenge masks true disorder-related molecular signatures, leading to poor reproducibility between studies and delaying critical diagnostic breakthroughs. Recent research demonstrates that correcting for this menstrual cycle bias reveals an average of 44.2% more genes in differential expression analysis, including 544 novel candidate genes for eutopic endometriosis that were previously obscured [7] [1].
This technical support center provides troubleshooting guides and experimental protocols to help researchers address menstrual cycle bias in their biomarker discovery workflows, enabling more accurate and reproducible findings in uterine disorder research.
Frequently Asked Questions (FAQs)
Q1: Why does menstrual cycle phase create such significant bias in endometrial biomarker studies?
The human endometrium is hormonally regulated and undergoes substantial molecular changes throughout the menstrual cycle. During the proliferative phase, estrogen drives endometrial growth, while the secretory phase is dominated by progesterone effects that prepare the endometrium for implantation. This hormonal regulation profoundly influences gene expression patterns, which can mask disease-specific signatures when not properly controlled [1] [30]. One study found that menstrual cycle phase accounted for the majority of variability in DNA methylation patterns within the endometrium, making it a major confounder in case-control studies [30].
Q2: What proportion of endometriosis studies properly account for menstrual cycle phase in their experimental design?
A systematic review of 35 endometrial transcriptomic studies found that 31.43% did not register the menstrual cycle phase at all in their experimental records. This represents a significant methodological gap in nearly one-third of studies in this field [7] [1].
Q3: What practical methods can I use to correct for menstrual cycle bias in my dataset?
The most effective approach uses linear models to remove menstrual cycle effects while preserving disease-related differential expression. The removeBatchEffect function implemented in the limma R package (v.3.30.13) has been successfully applied for this purpose, specifying the menstrual cycle phase as the batch to remove while defining the design matrix to preserve case versus control differences [1].
Q4: How much can statistical power improve after menstrual cycle bias correction?
Studies implementing menstrual cycle bias correction have demonstrated substantial improvements. One analysis of 12 datasets found that correcting for menstrual cycle bias revealed 44.2% more genes on average compared to uncorrected analyses. This method also showed greater statistical power than conducting separate per-phase analyses, retrieving more candidate genes with false discovery rate (FDR) < 0.05 [1].
Q5: What are the clinical implications of overcoming menstrual cycle bias in endometriosis research?
Endometriosis currently has a diagnostic latency of 7-11 years from symptom onset to definitive diagnosis, primarily because laparoscopy remains the gold standard for diagnosis. The discovery of reliable molecular biomarkers through properly controlled studies could enable non-invasive diagnostic tests, dramatically reducing this delay and allowing earlier intervention [31].
Troubleshooting Guides
Problem 1: Inconsistent Results Across Menstrual Cycle Phases
Symptoms: Significant variation in gene expression profiles when samples are collected across different menstrual cycle phases; poor reproducibility between studies; difficulty distinguishing disease-specific signals from normal cyclic variation.
Investigation Steps:
- Document Phase Precisely: Record the menstrual cycle phase for every endometrial sample using multiple dating methods where possible (LH peak timing, histological dating, ultrasound findings).
- Analyze Phase Distribution: Use Fisher's exact test to compare the proportion of samples collected at different endometrial stages between case and control groups [1].
- Visualize Batch Effects: Create principal component analysis (PCA) plots colored by menstrual cycle phase to visualize how much variance is explained by cycle phase versus disease status [1].
Solutions:
- Implement Linear Model Correction: Apply the
removeBatchEffectfunction from thelimmaR package, specifying menstrual cycle phase as the batch effect to remove while preserving case-control differences [1]. - Balance Study Design: When possible, ensure case and control groups are matched for menstrual cycle phase distribution during participant recruitment.
Verification:
- Re-run differential expression analysis after correction and compare the number of significant genes (FDR < 0.05) with pre-correction results.
- Validate that known phase-specific genes are no longer significant in the corrected analysis, while putative disease markers remain significant.
Problem 2: Low Statistical Power in Stratified Analysis
Symptoms: When analyzing data separately by menstrual cycle phase, individual analyses yield few significant genes due to reduced sample size in each subgroup.
Investigation Steps:
- Evaluate sample sizes within each menstrual cycle phase subgroup.
- Check the variance explained by menstrual cycle phase using PC-PR2 analysis [30].
- Compare the number of differentially expressed genes in phase-stratified analysis versus bias-corrected analysis.
Solutions:
- Use menstrual cycle bias correction instead of stratified analysis to preserve statistical power.
- Apply the unified linear model approach that corrects for cycle effects while testing case-control differences across the entire dataset [1].
Verification:
- Conduct power analysis to confirm improved detection capability.
- Compare results with the alternative approach of phase-stratified analysis to confirm superior gene detection.
Table 1: Impact of Menstrual Cycle Bias Correction on Gene Discovery in Uterine Disorders
| Condition | Genes Identified Without Correction | Additional Genes Revealed After Correction | Percentage Increase |
|---|---|---|---|
| Eutopic Endometriosis | Not reported | 544 novel candidates | 44.2% average across studies |
| Ectopic Ovarian Endometriosis | Not reported | 158 genes | 44.2% average across studies |
| Recurrent Implantation Failure | Not reported | 27 genes | 44.2% average across studies |
Table 2: Menstrual Cycle Phase Contribution to Molecular Variance in Endometrial Studies
| Data Type | Variance Explained by Menstrual Cycle Phase | Analysis Method |
|---|---|---|
| DNA Methylation | 2.99% of overall methylation variation (increased to 4.30% after SVA correction) | PC-PR2 analysis [30] |
| Gene Expression | Major source of bias, accounting for ~44.2% of missed findings | Linear models [1] |
| Differential Methylation | 9,654 differentially methylated sites between secretory vs. proliferative phases | Illumina Infinium MethylationEPIC Beadchip [30] |
Experimental Protocols
Protocol 1: Menstrual Cycle Bias Correction for Transcriptomic Data
Purpose: To remove menstrual cycle effects from endometrial gene expression data while preserving disease-related differential expression signals.
Materials and Reagents:
- Raw gene expression data from endometrial biopsies
- Clinical metadata including menstrual cycle phase for all samples
- R statistical environment (v.3.6.1 or higher)
- limma R package (v.3.30.13)
- ggplot2 package for visualization
Methodology:
- Data Pre-processing:
- Download and pre-process raw data using platform-specific methods
- For microarray data: use
affypackage for Affymetrix platforms orlimmafor Agilent/Illumina platforms - Apply quantile normalization between samples
- Annotate probesets to gene symbols using
biomaRtpackage
Exploratory Analysis:
- Detect and correct for technical batch effects using linear models
- Perform PCA with samples colored by menstrual cycle phase to visualize phase-related clustering
- Compare phase distribution between case and control groups using Fisher's exact test
Bias Correction:
- Use
removeBatchEffectfunction fromlimmapackage - Specify menstrual cycle phase as the batch to remove
- Define design matrix to preserve case versus control differences
- Apply FDR < 0.05 for significance threshold in subsequent differential expression analysis [1]
- Use
Validation:
- Compare the number of differentially expressed genes before and after correction
- Verify that known menstrual cycle-regulated genes are no longer differentially expressed between cases and controls after correction
- Confirm that putative disease biomarkers remain significant after correction
Protocol 2: Endometrial Tissue Collection and Phase Determination
Purpose: To standardize endometrial biopsy collection and accurate menstrual cycle phase determination for biomarker studies.
Materials and Reagents:
- Endometrial biopsy pipelle or curette
- RNA preservation solution (RNAlater or similar)
- Materials for histological dating (formalin, paraffin, staining reagents)
- LH surge detection kits (if planning timed biopsies)
Methodology:
- Participant Selection:
- Include women with regular menstrual cycles (25-35 days)
- Exclude those using hormonal medications in past 3 months
- Document detailed menstrual history
Cycle Phase Determination:
- Calculate cycle day from last menstrual period
- Confirm ovulation timing through LH surge detection kits or serum progesterone measurements
- Classify phases as: proliferative (days 5-14), early secretory (days 16-20), mid-secretory (days 21-23), or late secretory (days 24-28)
Tissue Collection and Processing:
- Obtain endometrial biopsies using standard clinical technique
- Immediately divide tissue aliquots for RNA, DNA, and histology
- Preserve RNA samples in RNAlater at -80°C
- Process histology samples for traditional dating per Noyes criteria [1]
Quality Control:
- Histological confirmation of endometrial dating
- RNA quality assessment (RIN > 7.0)
- Documentation of any discrepancies between chronological and histological dating
Visualizing the Experimental Workflow
Experimental Workflow for Menstrual Cycle Bias Correction
The Scientist's Toolkit: Essential Research Reagents and Solutions
Table 3: Essential Research Reagents and Computational Tools for Menstrual Cycle Bias Correction
| Tool/Reagent | Function/Purpose | Specific Application Notes |
|---|---|---|
| limma R Package | Differential expression analysis with batch effect correction | Use removeBatchEffect function specifying menstrual cycle phase as batch; preserves case-control differences [1] |
| Endometrial Biopsy Pipelle | Minimally invasive tissue collection | Enables collection of endometrial samples for transcriptomic and methylation analysis |
| RNA Preservation Solution | Stabilizes RNA for transcriptomic studies | Critical for preserving RNA integrity during sample processing and storage |
| Illumina MethylationEPIC BeadChip | Genome-wide DNA methylation profiling | Used in studies identifying 9,654 differentially methylated sites across menstrual cycle [30] |
| LH Surge Detection Kits | Precise ovulation timing | Enables accurate menstrual cycle phase determination for sample collection timing |
| BiomaRt R Package | Genomic data annotation | Converts probe set IDs to gene symbols for functional interpretation of results |
| Weighted Gene Co-expression Network Analysis (WGCNA) | Module identification in transcriptomic data | Identifies gene clusters associated with endometriosis independent of cycle effects [32] |
Advanced Applications and Future Directions
The principles of menstrual cycle bias correction extend beyond transcriptomic analysis to other omics fields. Recent DNA methylation studies demonstrate that menstrual cycle phase explains approximately 2.99-4.30% of overall methylation variation in endometrial tissue, with 9,654 differentially methylated sites identified between proliferative and secretory phases [30]. This epigenetic dimension further emphasizes the necessity of accounting for cycle effects in comprehensive multi-omics approaches to endometriosis research.
Furthermore, emerging methodologies combining machine learning approaches with bias-corrected data show promise for identifying robust biomarker panels. Studies utilizing LASSO, random forest, and support vector machine algorithms on corrected datasets have identified novel candidate genes like CHMP4C and KAT2B that may contribute to endometriosis pathogenesis through immune cell infiltration regulation [32]. These approaches represent the next frontier in developing clinically applicable diagnostic tools from fundamental biomarker discovery research.
Frequently Asked Questions
Q1: Why is the menstrual cycle a major confounding factor in female biomarker discovery? The menstrual cycle is a major source of confounding because hormonal fluctuations cause widespread molecular changes in tissues beyond the endometrium. In gene expression studies, the timing of the menstrual cycle often emerges as the dominant source of variation in the data, sometimes explaining more variance than the pathological condition under investigation. If this effect is not statistically controlled, it can mask disease-related signals and lead to both false positives and false negatives [1] [20].
Q2: What is the minimum sample size required to account for cycle phase in biomarker studies? While there is no universal minimum, the key is to ensure a balanced distribution of samples across all relevant cycle phases in both case and control groups. A common pitfall is underpowered studies. One analysis of 12 endometrial gene expression studies found that nearly a third (31%) did not record any menstrual cycle phase information at all, and 37% collected samples in only a broad phase (e.g., proliferative or secretory) without further subdivision, severely limiting their analytical power [20].
Q3: Can I pool samples from different menstrual cycle phases if I am not studying a reproductive condition? No. Even when studying non-reproductive diseases, the systemic hormonal changes of the menstrual cycle can influence biomarkers in fluids like blood and urine, as well as other tissues. Pooling samples without accounting for this introduces significant, unmeasured noise. The recommended practice is to record the cycle phase meticulously and include it as a covariate in statistical models to remove this unwanted variation [1] [20].
Q4: My case and control groups are imbalanced in their cycle phase distribution. How can I correct for this in my analysis?
This is a common challenge. Statistical methods can correct for this bias post-hoc. You can use linear models with functions like removeBatchEffect (from the limma R package) to subtract the variation caused by the menstrual cycle while preserving the variation due to the case-control status. One study demonstrated that this approach identified 44.2% more candidate genes on average after removing menstrual cycle bias, significantly increasing statistical power [1].
Q5: Are there specific biomarkers whose levels are known to be stable across the menstrual cycle? The stability of most biomarkers across the cycle is not fully known, which is precisely why a cycle-aware framework is essential. The goal is to discover which biomarkers are truly disease-specific versus those that are cycle-influenced. For example, a novel endometrial gene signature (the Endometrial Failure Risk signature) was only identified after correcting for luteal phase timing, revealing a disruption independent of timing in 73.7% of patients [29].
Troubleshooting Guides
Problem: Inconsistent or Non-Replicable Biomarker Signatures
Symptoms:
- Biomarker candidates from your study do not overlap with those from other studies on the same condition.
- Effect sizes for your biomarkers diminish or disappear in validation cohorts.
- You identify hundreds or thousands of differentially expressed genes, but they do not form a consistent biological narrative [1] [20].
Solutions:
- Improve Meta-Data Collection: For every sample—whether it's serum, plasma, or other tissues—record the first day of the last menstrual period and/or the estimated cycle day. If possible, use hormonal measurements (e.g., LH surge kits, serum progesterone) to objectify the cycle phase [20] [33].
- Implement Statistical Correction: Use a linear model to statistically remove the variation in your data that is attributable to the menstrual cycle phase.
- Workflow:
- Step 1: Annotate each sample with its menstrual cycle phase (e.g., proliferative, early secretory, mid-secretory, late secretory) or a more precise molecular timing estimate if available.
- Step 2: In your differential analysis (e.g., using the
limmapackage in R), include the cycle phase as a covariate in the design matrix. - Step 3: Proceed with the standard analysis to identify biomarkers. This will now reveal differences that are independent of the natural cycle variation [1].
- Workflow:
- Validate with a Balanced Cohort: If possible, validate your initial findings in a new, independent cohort where the case and control groups are perfectly matched for menstrual cycle phase at the time of sample collection.
Problem: Low Statistical Power in Subgroup Analyses
Symptoms:
- When you stratify your samples by cycle phase to avoid confounding, the sample size in each group becomes too small for meaningful analysis.
- You are unable to detect statistically significant biomarker differences, even when clinical differences are apparent.
Solutions:
- Use Molecular Dating for Precision: Instead of broad histological phases (e.g., "secretory"), use a molecular assay to estimate a more precise "cycle time" for each sample. This continuous variable can be more powerfully modeled than categorical phase labels [20].
- Increase Sample Size with Power Analysis: Conduct an a priori power calculation that accounts for the need to control for the cycle phase. This will often require a larger total sample size than a standard study. Resources like [33] provide guidance on power estimation for biomarker studies.
- Leverage Public Data: Re-analyze public datasets (e.g., from GEO) that have cycle phase metadata using your cycle-aware framework. This can help validate your methods and generate new hypotheses without additional sample collection [1] [20].
Quantitative Evidence for Cycle Bias and Correction
The following table summarizes key quantitative findings from studies that have investigated and corrected for menstrual cycle bias.
Table 1: Impact of Menstrual Cycle Bias and Correction in Biomarker Studies
| Study Focus | Key Finding on Bias | Impact of Correction | Reference |
|---|---|---|---|
| Endometrial Transcriptomics (Various pathologies) | 31.4% (11/35) of studies did not register the menstrual cycle phase. | After correction, 44.2% more genes were identified on average. 544 novel candidate genes discovered for endometriosis. | [1] |
| Endometrial Receptivity (Hormone Replacement Therapy cycles) | Endometrial luteal phase timing is a major source of gene expression variation. | A novel Endometrial Failure Risk (EFR) signature was identified, independent of timing. It stratified patients into groups with 25.6% vs 77.6% live birth rates. | [29] |
| Endometriosis & Recurrent Implantation Failure (RIF) | Analysis of 4 endometriosis studies found only 6 overlapping genes; 7 RIF studies had only 1 gene overlapping 3+ studies. | Correction methods increased statistical power, retrieving more candidate genes than analyzing each phase independently. | [1] [20] |
Experimental Protocols
Protocol 1: Correcting for Menstrual Cycle Bias in Transcriptomic Data Analysis
This protocol is adapted from the methodology described by Devesa-Peiro et al. (2021) and is applicable to gene expression data from microarrays or RNA-Seq [1].
1. Pre-processing and Quality Control
- Input: Raw gene expression data files and a sample meta-data table that includes the menstrual cycle phase for each sample.
- Software: R programming environment.
- Steps:
- Normalize the data using appropriate methods (e.g.,
quantilenormalization for microarrays,edgeRorDESeq2for RNA-Seq). - Perform an exploratory Principal Component Analysis (PCA). Visual Check: The first or second principal component will often separate samples by their menstrual cycle phase, illustrating the scale of this effect [20].
- Normalize the data using appropriate methods (e.g.,
2. Menstrual Cycle Effect Correction
- Tool:
removeBatchEffectfunction from thelimmaR package (v.3.30.13 or higher). - Rationale: This function uses a linear model to remove variation associated with a known batch effect (the cycle phase) while preserving the variation due to your primary variable of interest (e.g., disease state).
- Code Example:
- Output: A corrected gene expression matrix where the influence of the menstrual cycle has been minimized.
3. Differential Expression Analysis
- Perform your standard case vs. control differential expression analysis on the
corrected_expressionmatrix using thelimmapackage. - The resulting list of differentially expressed genes will be more specific to the pathology and less confounded by the cycle.
Protocol 2: Designing a Cycle-Aware Biomarker Discovery Study
This protocol outlines best practices for the design phase, crucial for preventing bias from being introduced [20] [33].
1. Cohort Selection and Stratification
- Action: Do not simply collect samples consecutively. Actively stratify recruitment to ensure a balanced number of case and control participants in each major menstrual cycle phase (Proliferative, Early Secretory, Mid-Secretory, Late Secretory).
- Documentation: Record the first day of the last menstrual period, cycle length, and, if feasible, confirm the phase with a urinary LH kit or a serum progesterone test.
2. Sample Size Estimation
- Action: Use power analysis software to determine the total sample size needed. Account for the fact that you will be dividing your samples into cycle phase groups or using phase as a covariate, which may require a larger N to achieve the same power.
- Consideration: Larger sample sizes help mitigate the inherent biological variability and improve the reliability of your findings [33].
3. Blinding and Randomization
- Blinding: The personnel processing the samples and performing the laboratory analyses should be blinded to both the case/control status and the menstrual cycle phase of the samples.
- Randomization: Process samples in a randomized order that is not correlated with the cycle phase or disease status to avoid technical batch effects confounding the biological signal [33].
Visualizing the Workflow: From Problem to Solution
The following diagram illustrates the conceptual and analytical workflow for implementing a cycle-aware framework in biomarker discovery.
The Scientist's Toolkit: Essential Research Reagents & Solutions
Table 2: Key Reagents and Tools for Cycle-Aware Biomarker Research
| Item | Function / Application | Considerations |
|---|---|---|
| Urinary Luteinizing Hormone (LH) Detection Kits | Objectively pinpoint the LH surge, defining the start of the secretory phase. | Crucial for precise timing of sample collection in the peri-ovulatory and secretory windows. |
| Progesterone & Estradiol ELISA/EIA Kits | Quantify serum hormone levels to objectively confirm menstrual cycle phase. | Provides a continuous variable for statistical modeling that can be more powerful than categorical phase labels. |
| PAXgene Blood RNA Tubes | Stabilize RNA in whole blood for transcriptomic studies of liquid biopsies. | Prevents gene expression changes post-phlebotomy, ensuring accurate measurements of systemic biomarkers. |
| RNeasy Protect Kit (or similar) | Preserve RNA from tissue biopsies (e.g., endometrium) immediately upon collection. | Maintains the integrity of the transcriptomic profile at the exact moment of collection. |
limma R Package |
The primary statistical tool for performing differential expression analysis and batch effect correction (e.g., removeBatchEffect). |
The cornerstone of the computational correction workflow [1]. |
| Molecular Dating Assay | A gene expression panel that estimates a molecular "time" for an endometrial sample within the cycle. | Provides a more precise and objective measure of endometrial progression than histology alone [20]. |
Overcoming Implementation Hurdles: From Sample Timing to Data Interpretation
For researchers in reproductive health, phased sample collection is a critical methodology for correcting menstrual cycle bias, a confounding variable that can mask genuine biomarkers for uterine disorders such as endometriosis and recurrent implantation failure [7]. This technical support center provides actionable troubleshooting guides and FAQs to help you design and execute robust collection protocols, ensuring the integrity of your biomarker discovery research.
Frequently Asked Questions (FAQs)
Why is the menstrual cycle phase a critical variable in endometrial biomarker studies? The endometrial transcriptome progresses significantly throughout the menstrual cycle. Failure to account for this progression introduces a major confounding variable. In fact, one systematic review found that after correcting for menstrual cycle bias, studies identified an average of 44.2% more genuine disorder-associated genes [7].
What is the consequence of not registering the menstrual cycle phase during sample collection? Omitting this information can severely compromise your research. A review of studies revealed that 31.43% of published papers did not register the menstrual cycle phase, meaning their findings on disorder-related genes are likely contaminated by cycle-related expression changes and may not be reproducible [7].
Should I collect samples from all cycle phases or just one? Both strategies can be valid if properly planned. However, cycle bias can mask biomarkers even in studies balanced across phases or those collecting samples only in the mid-secretory phase. The key is to statistically account for the cycle phase during your data analysis, for example by using linear models to remove this source of variation [7].
We have a limited budget. What is the most efficient way to phase samples? A phased implementation strategy is highly recommended for managing complex projects with limited resources. Instead of a "big bang" approach, automate and optimize your workflows one phase at a time. This reduces risk, allows your team to adapt gradually, and delivers value faster by focusing on the most critical components first [34].
Troubleshooting Guides
Problem: Inconsistent Sample Classification Leading to Unreliable Data
- Symptoms: High variability in biomarker levels within experimental groups, inability to replicate your own findings, and poor statistical power in differential expression analysis.
- Root Cause: Inaccurate or imprecise determination of the menstrual cycle phase for each collected tissue sample.
Solution: Implement a Standardized Cycle Phase Determination Protocol
Follow this step-by-step guide to establish a consistent and reliable classification system.
- Define Criteria A Priori: Before collecting the first sample, document the precise morphological criteria (e.g., histology by a certified pathologist) or hormonal thresholds (e.g., serum progesterone levels) that will define each cycle phase (Proliferative, Early Secretory, Mid Secretory, Late Secretory) [7].
- Collect Supporting Data: For each participant, gather the necessary data for classification. This must include:
- First Day of Last Menstrual Period (LMP)
- Next First Day of Menstrual Period (for cycle length calculation)
- Histological dating of the endometrial biopsy
- Serum hormone levels (e.g., Estradiol, Progesterone) at the time of biopsy [7]
- Centralized Review: Have all histological and hormonal data reviewed by a single individual or a small, calibrated committee to minimize inter-observer variation.
- Document and Lock Classifications: Record the final cycle phase for each sample in a secure database. This classification should be treated as a fixed variable in subsequent analyses.
Visual Workflow for Sample Classification
The diagram below outlines the logical workflow for standardizing sample classification to minimize cycle phase bias.
Problem: Low Sample Yield or Quality Due to Collection Issues
- Symptoms: Insufficient RNA/DNA for sequencing, degraded biomolecules, or high sample failure rates.
- Root Cause: Inefficient or damaging collection techniques, improper sample pre-treatment, or failure to quickly stabilize biomolecules.
Solution: Optimize Pre-Analytical Sample Handling
This guide outlines best practices for sample preparation, drawing from established laboratory techniques to ensure sample integrity from collection to analysis [35].
- Sample Pre-Treatment: Optimize the sample for effective analyte retention.
- Dilution: Dilute viscous or complex matrices like serum, plasma, or urine with an equal volume of suitable buffer or water [35].
- pH Adjustment: Ensure the sample is at the proper pH for optimum retention of your target analytes [35].
- Particulate Removal: Remove unwanted particulates by filtration or centrifugation to prevent column clogging [35].
- Immediate Stabilization: Snap-freeze tissue biopsies in liquid nitrogen immediately after collection to halt RNA degradation and preserve the biomolecular snapshot of the cycle phase.
- Standardize Collection Tools: Use the same type and size of biopsy catheter across all patients and collection timepoints to minimize tissue trauma and variation.
The Scientist's Toolkit
The following table details key materials and their functions for successful phased sample collection and analysis.
| Item | Function in Phased Collection |
|---|---|
| Standardized Biopsy Kit | Ensures consistent tissue collection across all patients and timepoints, reducing technical variation. |
| RNA Stabilization Solution | Preserves the transcriptome instantly upon collection, "freezing" the gene expression profile of the specific cycle phase. |
| Liquid Nitrogen Dewar | Provides immediate snap-freezing and long-term storage of samples at -80°C or below, preserving labile biomolecules. |
| Laboratory Information Management System (LIMS) | Tracks critical metadata for each sample (Patient ID, LMP, histology date, hormone levels, freezer location), preventing data loss and misclassification [34]. |
| Buffer Solutions (e.g., PBS) | Used for diluting and homogenizing samples during pre-treatment to optimize them for downstream analysis like solid-phase extraction [35]. |
| Solid Phase Extraction (SPE) Cartridges | A sample preparation technique used to remove interfering compounds from a complex sample matrix (like homogenized tissue) or to concentrate analytes of interest prior to analysis, improving assay sensitivity [35]. |
Troubleshooting Guides
Guide 1: Resolving Poor Replication of Biomarker Candidates
Problem: Your study identifies hundreds of differentially expressed biomarkers, but these findings fail to replicate in validation cohorts or subsequent studies.
Explanation: This is a classic symptom of improperly controlled menstrual cycle bias. The endometrial tissue is highly dynamic, with thousands of genes showing expression changes throughout the menstrual cycle [20]. When this major source of variation is not accounted for, cycle-induced expression changes can be misinterpreted as disease-associated signals, leading to false positives and irreproducible results.
Solution: Implement continuous cycle timing correction instead of categorical phase grouping.
- Root Cause: Menstrual cycle stage often explains more variance in omics data than the experimental condition itself. Principal component analyses frequently show cycle time as the dominant factor in PC1 and PC2 [20].
- Immediate Action: Re-analyze existing data using molecular dating or continuous cycle time as a covariate in statistical models.
- Preventive Measure: For future studies, plan for precise cycle timing measurement using molecular methods (e.g., transcriptomic dating) rather than relying solely on histological dating or patient self-reporting.
Guide 2: Addressing Underpowered Analyses Despite Adequate Sample Sizes
Problem: Your study has sufficient participants based on initial power calculations, but statistical power remains low for detecting true biomarker effects.
Explanation: Traditional per-phase analyses dramatically reduce statistical power by artificially splitting continuous biological processes into arbitrary categorical groups and reducing analyzable sample size in each group. This approach fails to account for substantial variability within each phase.
Solution: Adopt bias correction methods that use the entire dataset while controlling for cycle effects.
- Root Cause: Per-phase analysis violates the principle of addressing multiple questions within a single experiment, a concern raised by R.A. Fisher himself [36]. Each sub-analysis has reduced sample size, increasing false negative rates.
- Immediate Action: Apply multivariate linear models that include continuous cycle time as a covariate alongside your primary variables of interest.
- Preventive Measure: Use adaptive trial designs and Bayesian methods that can accommodate complex, time-dependent covariates without sacrificing power [36].
Frequently Asked Questions (FAQs)
Why is traditional per-phase analysis insufficient for controlling menstrual cycle effects?
Per-phase analysis is insufficient because it treats the menstrual cycle as distinct categorical states rather than a continuous biological process. Systematic reviews of endometrial research have demonstrated concerning reproducibility issues, with minimal overlap of identified genes between studies examining the same pathology [20]. For instance, across four endometriosis studies, only six genes overlapped between at least two studies out of 1,307 total candidate genes identified [20]. This approach fails because:
- Substantial Within-Phase Variation: Significant molecular changes occur within traditionally defined phases, with some genes changing expression over approximately 24-hour windows [20].
- Arbitrary Phase Boundaries: Conventional histological dating lacks the precision needed for molecular studies [20].
- Reduced Statistical Power: Splitting data into phases reduces sample size for each analysis, increasing false negative rates.
What quantitative evidence demonstrates the superiority of bias correction methods?
Direct comparisons in re-analyses of published datasets show dramatic improvements when proper cycle correction is applied:
Table 1: Performance Comparison of Statistical Methods for Menstrual Cycle Correction
| Method | Key Principle | Statistical Power | False Discovery Rate | Implementation Complexity |
|---|---|---|---|---|
| Per-Phase Analysis | Splits data into categorical phases (menstrual, follicular, ovulatory, luteal) | Low (reduced sample size per analysis) | High (phase effects misattributed to condition) | Low |
| Bias Correction | Models cycle time as continuous covariate in multivariate models | High (uses full dataset) | Properly controlled | Medium |
| Molecular Timing | Uses transcriptomic data to estimate precise cycle time | Highest (accounts for individual variability) | Best controlled | High |
Data from re-analysis of 12 endometrial gene expression studies showed that proper menstrual cycle stage correction increased statistical power by an average of 44% compared to uncorrected analyses or per-phase approaches [20].
How can researchers precisely determine menstrual cycle timing for bias correction?
Advanced methods now enable more precise cycle timing than traditional histological dating:
Table 2: Methods for Menstrual Cycle Phase Determination in Research Settings
| Method | Principle | Precision | Advantages | Limitations |
|---|---|---|---|---|
| Histological Dating | Noyes' criteria based on tissue morphology | Low (5-7 day error) [20] | Widely available, inexpensive | Subjective, imprecise for molecular studies |
| Hormone Measurement | Serum levels of E2, P4, LH | Medium (2-3 day error) | Objective quantitative measure | Single time point may miss dynamics |
| Molecular Dating | Transcriptomic patterns from RNA-seq | High (1-2 day error) [20] | High precision, objective | Requires specialized computational analysis |
| Wearable Sensors | Machine learning on physiological data (skin temp, HR, HRV) | Medium-High [37] | Continuous, non-invasive | Requires validation for research use |
Machine learning approaches applied to wearable sensor data (skin temperature, heart rate, heart rate variability) can classify menstrual phases with up to 87% accuracy for three-phase classification [37].
What are the practical implementation steps for bias correction methods?
During Study Design:
- Plan for precise cycle timing measurement using hormonal assessment or molecular methods
- Ensure adequate sample size for multivariate modeling
- Consider adaptive designs that can accommodate cycle-related variability [36]
Data Collection:
- Collect detailed cycle history and timing data for each participant
- Use standardized protocols for tissue collection and processing
- Consider wearable sensors for continuous physiological monitoring [37]
Statistical Analysis:
- Implement linear models with cycle time as a continuous covariate:
Expression ~ Condition + CycleTime + Covariates - For molecular data, use transcriptomic dating to estimate precise cycle time
- Validate findings in independent cohorts with similar cycle timing data
- Implement linear models with cycle time as a continuous covariate:
How does bias correction align with modern clinical trial innovation trends?
Bias correction methods align perfectly with contemporary shifts toward more efficient, informative trial designs:
- Adaptive Designs: Bayesian adaptive methods enable trials to accommodate complex variables like menstrual cycle effects without sacrificing integrity [36]
- Risk-Based Approaches: Focusing on critical quality factors like proper cycle control represents a risk-proportionate approach to data management [38]
- Clinical Data Science: The transition from operational data management to strategic data science emphasizes generating insights through proper modeling of biological variables [38]
Experimental Protocols
Protocol 1: Transcriptomic Dating for Menstrual Cycle Timing
Purpose: To determine precise menstrual cycle timing for statistical bias correction in endometrial biomarker studies.
Materials:
- Endometrial tissue samples
- RNA extraction kit (e.g., Qiagen RNeasy)
- RNA sequencing library preparation reagents
- Sequencing platform (Illumina recommended)
- Computational resources for RNA-seq analysis
Procedure:
- Extract high-quality RNA from endometrial tissue samples
- Prepare RNA-seq libraries using standardized protocols
- Sequence libraries to adequate depth (recommended: 30M reads per sample)
- Process raw sequencing data through quality control and normalization pipelines
- Apply transcriptomic dating algorithms to estimate cycle time based on known phase-specific gene expression patterns
- Use estimated cycle times as continuous covariates in downstream differential expression analyses
Validation: Correlate molecular timing estimates with serum hormone measurements (estradiol, progesterone) when available [20].
Protocol 2: Multivariate Modeling with Continuous Cycle Correction
Purpose: To implement statistical bias correction for menstrual cycle effects in biomarker discovery analyses.
Materials:
- Processed omics data (e.g., normalized gene expression matrix)
- Clinical metadata including cycle timing information
- Statistical computing environment (R or Python recommended)
Procedure:
- Prepare data matrix with normalized expression values, condition labels, and cycle timing variables
- Implement linear model accounting for cycle effects:
lm(expression ~ condition + cycle_time + age + other_covariates) - For high-dimensional omics data, use appropriate multiple testing correction (Benjamini-Hochberg FDR)
- Compare results with and without cycle correction to assess impact on findings
- Validate identified biomarkers in independent datasets with available cycle timing data
Troubleshooting: If model convergence issues occur with small sample sizes, consider Bayesian hierarchical models with regularizing priors [36].
Research Workflow and Signaling Pathways
Menstrual Cycle Bias Correction Workflow
Hormonal Regulation of Endometrial Gene Expression
The Scientist's Toolkit
Research Reagent Solutions
Table 3: Essential Materials for Menstrual Cycle Research
| Reagent/Resource | Function | Example Applications |
|---|---|---|
| RNA Stabilization Reagents (e.g., RNAlater) | Preserves RNA integrity for transcriptomic studies | Molecular dating of endometrial samples [20] |
| Hormone Assay Kits (E2, P4, LH) | Quantifies serum hormone levels | Objective cycle phase confirmation [39] |
| Wearable Sensors (EDA, temp, HR) | Continuous physiological monitoring | Machine learning-based phase classification [37] |
| RNA-seq Library Prep Kits | Preparation of sequencing libraries | Genome-wide expression profiling for biomarker discovery [20] |
| Statistical Software (R, Python) | Implementation of bias correction models | Multivariate modeling with cycle time covariates [20] |
Frequently Asked Questions
1. Why is balancing the menstrual cycle stage across study cohorts so important? Variations in the menstrual cycle introduce significant hormonal variability, which can confound the measurement of biomarkers and lead to inaccurate or irreproducible research findings. Properly balancing or accounting for this factor is essential for the validity of studies involving reproductive-aged women [40] [41].
2. What is the most reliable method for defining menstrual cycle phases in a research setting? The most rigorous method is a longitudinal design that confirms cycle phases through hormone assays (e.g., estradiol, progesterone) rather than relying on calendar counting alone. Self-reported cycle days can be inaccurate; hormonal confirmation provides objective phase assignment and helps identify anovulatory cycles that should be excluded from analysis [41].
3. How can I account for the menstrual cycle in a cross-sectional study? For cross-sectional studies, you can treat the menstrual cycle phase as a key stratification variable. During participant recruitment, you should systematically record the cycle phase (confirmed by a combination of backward counting from the last menstrual period and hormonal tests if feasible) and ensure your experimental and control groups are balanced for the distribution of these phases [41].
4. Our study has already collected data without recording cycle stage. What can we do? If the data has already been collected, you can use statistical methods to control for the potential confounding effect. This involves including the cycle phase (if retrospectively attainable from medical records or participant recall) or using proxy variables as covariates in your analytical models. However, this is less ideal than prospective design [42].
5. Are there specific biomarkers that are particularly sensitive to cycle stage? Yes, several biomarkers are hormonally sensitive. For instance, CA-125, a protein used in ovarian cancer research, is known to fluctuate during the menstrual cycle and can be elevated in non-cancerous conditions like endometriosis. It is crucial to account for the cycle phase when measuring such biomarkers to avoid misdiagnosis or false positives [43].
Troubleshooting Common Experimental Challenges
Problem: Inconsistent Biomarker Measurements Across Participants
Issue: You observe high variability in your primary biomarker readings, which you suspect is due to unaccounted-for menstrual cycle stages. Solution:
- Prospective Phase Stratification: For your next study phase, adopt a longitudinal design where each participant is measured at multiple, hormonally-confirmed cycle phases (e.g., menses, peri-ovulatory, and mid-luteal). This allows participants to serve as their own controls [41].
- Statistical Control: In your current analysis, if you have data on cycle phases, include phase as a fixed effect in your linear mixed models. If hormone levels (estradiol, progesterone) were measured, you can model the biomarker outcome as a function of these continuous hormone levels to account for the specific hormonal milieu [41].
Problem: Recruiting Participants in Specific Cycle Phases is Slowing Down Your Study
Issue: Waiting for participants to reach a specific, hormonally-confirmed cycle phase (like the peri-ovulatory phase) causes significant delays. Solution:
- Adapt the Study Design: Instead of a purely longitudinal design, consider a cross-sectional approach with balanced enrollment. Plan to recruit a separate group of participants for each cycle phase of interest (menses, peri-ovulatory, luteal). This allows for parallel enrollment and can be powered to detect effects across phases [41].
- Use a Prescreened Cohort: Utilize existing cohorts with detailed baseline data. You can apply a balanced sampling technique to select a subcohort from a larger pool where some cycle information is already available, ensuring the selected groups are comparable on key auxiliary variables [44].
Problem: Managing Complex Data from Longitudinal Tracking
Issue: You are collecting daily hormone data or symptom tracking from a mobile app across multiple cycles, but the data management and analysis are becoming overwhelming. Solution:
- Standardized Digital Protocols: Implement a standardized data processing pipeline. Leverage validated mobile health (mHealth) platforms and specify in your statistical analysis plan how you will handle missing data and define cycle phases algorithmically from the tracking data [40] [42].
- Define a Clear Primary Endpoint: Pre-specify your primary cycle-related outcome (e.g., mean cycle length, hormone level at a specific phase, presence of ovulation) to focus the analysis. The Apple Women's Health Study, for example, used mixed models to analyze cycle length and variability, adjusting for age, ethnicity, and BMI [40].
Evidence-Based Menstrual Cycle Variations
The following table summarizes key demographic factors that significantly influence menstrual cycle characteristics, based on a large-scale digital cohort study. These factors should be considered as potential confounders or effect modifiers when designing your study and balancing cohorts [40].
Table 1: Factors Influencing Menstrual Cycle Length and Variability
| Factor | Comparison | Difference in Mean Cycle Length (Days) | Impact on Cycle Variability |
|---|---|---|---|
| Age | < 20 vs. 35-39 (ref) | +1.6 days | 46% higher |
| 45-49 vs. 35-39 (ref) | -0.3 days | 45% higher | |
| > 50 vs. 35-39 (ref) | +2.0 days | 200% higher | |
| Ethnicity | Asian vs. White (ref) | +1.6 days | Larger variability |
| Hispanic vs. White (ref) | +0.7 days | Larger variability | |
| Obesity Status (BMI) | BMI ≥ 40 vs. Healthy BMI (ref) | +1.5 days | Higher variability |
Experimental Protocols for Cohort Balancing
Protocol 1: Longitudinal Design with Hormonal Confirmation
This is the gold-standard approach for studying changes within individuals across their cycle [41].
- Participant Screening: Recruit healthy, premenopausal women with a history of regular menstrual cycles (21-35 days). Exclude those using hormonal contraception or other medications known to affect cycle regularity.
- Cycle Phase Determination: Schedule testing sessions for three key phases:
- Menses (Early Follicular): Days 2-5 after the onset of menstruation. Confirm low levels of estradiol and progesterone.
- Peri-Ovulatory: Correlate with a urinary luteinizing hormone (LH) surge or a serum progesterone level of > 3 ng/mL 7 days post-positive LH test.
- Mid-Luteal: Approximately 7 days after the confirmed ovulation.
- Sample Collection: Collect biological samples (blood, urine) for your biomarker of interest and for hormone assays (estradiol, progesterone) at each visit.
- Data Analysis: Use linear mixed-effects models to analyze biomarker data, with cycle phase as a fixed effect and participant ID as a random effect.
Protocol 2: Cross-Sectional Design with Stratified Enrollment
This protocol is more feasible for large studies and allows for faster enrollment [41].
- Stratified Recruitment: Based on a priori power calculations, plan to enroll a pre-determined number of participants into each of the three cycle phase groups (Menses, Peri-Ovulatory, Luteal).
- Phase Assignment: Upon enrollment, determine the participant's current cycle phase using a combination of last menstrual period (LMP) date and a rapid urinary LH test or a single serum progesterone test to confirm the phase.
- Group Matching: Ensure that the groups enrolled in different cycle phases are matched for other important covariates such as age, BMI, and ethnicity (see Table 1).
- Single Time-Point Measurement: Collect all biomarker and outcome data at this single, confirmed visit.
- Data Analysis: Use analysis of covariance (ANCOVA) to compare biomarker levels across the three cycle phase groups, adjusting for relevant covariates like age and BMI.
The Scientist's Toolkit
Table 2: Essential Reagents and Resources for Menstrual Cycle Research
| Item | Function/Application in Research |
|---|---|
| Urinary LH Test Kits | At-home or clinic-based detection of the luteinizing hormone surge to pinpoint ovulation and define the peri-ovulatory phase. |
| ELISA Kits for Estradiol & Progesterone | Quantify serum or saliva levels of key ovarian hormones to objectively confirm menstrual cycle phases. |
| Fertility Awareness Method (FAM) Charts | Standardized paper or digital charts for participants to track basal body temperature (BBT) and cervical mucus, providing longitudinal cycle data [45]. |
| Validated Mobile Health Apps | Applications that incorporate FAMs to facilitate real-time, digital data collection on menstrual symptoms and cycle length from participants [46]. |
| Dried Blood Spot Cards | A cost-effective and convenient method for participants to self-collect capillary blood samples for subsequent hormone analysis. |
Workflow: Strategy Selection for Cohort Balancing
The following diagram outlines a logical pathway for choosing the most appropriate cohort balancing method based on your study's design and constraints.
Diagram 1: A decision workflow for selecting a method to address menstrual cycle stages in study cohorts.
In the field of biomarker discovery, failing to account for the menstrual cycle introduces significant confounding bias that can mask genuine pathological signatures. Research demonstrates that correcting for menstrual cycle bias reveals substantially more candidate genes associated with uterine disorders—on average, 44.2% more genes were identified after removing this bias using linear models [7]. This approach has led to the discovery of hundreds of novel candidate genes for endometriosis and recurrent implantation failure [7].
The broader challenge of data integration—combining data from multiple sources into a unified, consumable form—provides essential methodology for addressing cycle-related confounding [47]. In systems biology, successful integration of diverse data types (transcriptomic, proteomic, etc.) has revealed emergent properties and system-level insights that would remain hidden in isolated analyses [48].
Key Terminology
- Reproducibility: Re-doing a study using similar methods and obtaining findings consistent with the original study [49]. A 2024 survey found that 72% of biomedical researchers agree there is a reproducibility crisis in biomedicine [49].
- Direct Replication: Efforts to reproduce a previously observed result using the same experimental design and conditions as the original study [50].
- Analytic Replication: Reproducing a series of scientific findings through reanalysis of the original dataset [50].
- Menstrual Cycle Bias: A confounding effect where molecular changes during endometrial progression mask disorder-related biomarkers [7].
Essential Methodologies and Workflows
Comprehensive Experimental Workflow for Cycle-Integrated Analysis
The following diagram outlines a robust methodology for integrating cycle data with other variables while controlling for potential biases.
Experimental Workflow for Cycle-Integrated Analysis
This workflow emphasizes several critical components for successful multifactorial analysis:
- Pre-registration: Registering study designs before initiation helps discourage suppression of negative results and allows careful scrutiny of all research processes [50].
- Comprehensive Annotation: Documenting menstrual cycle phase through histological dating of endometrial tissue is essential for subsequent bias correction [7].
- Multi-omics Integration: Combining data from transcriptomics, proteomics, and other molecular profiling platforms increases coverage and power of pathway analysis [51].
- Validation: Independent cohort validation and functional experiments are necessary to confirm biomarker candidates identified through integrated analysis.
Quantitative Impact of Cycle Bias Correction
The table below summarizes key quantitative findings from research on menstrual cycle bias correction in endometrial studies.
Table 1: Impact of Menstrual Cycle Bias Correction on Biomarker Discovery
| Metric | Value Before Correction | Value After Correction | Change | Context |
|---|---|---|---|---|
| Genes Identified | Baseline | +44.2% more genes | +44.2% | Average increase across 12 studies after removing menstrual cycle bias using linear models [7] |
| Novel Endometriosis Genes | Not discovered | 544 genes discovered | N/A | Eutopic endometriosis candidates revealed after bias correction [7] |
| Ovarian Endometriosis Genes | Not discovered | 158 genes discovered | N/A | Ectopic ovarian endometriosis candidates revealed after bias correction [7] |
| RIF-associated Genes | Not discovered | 27 genes discovered | N/A | Recurrent implantation failure candidates revealed after bias correction [7] |
| Studies Not Registering Cycle Phase | 31.43% | N/A | N/A | Percentage of endometrial biomarker studies that did not register menstrual cycle phase [7] |
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Research Materials and Tools for Cycle-Integrated Studies
| Category | Specific Tool/Reagent | Function in Research | Key Considerations |
|---|---|---|---|
| Bioinformatics Tools | Multiple Co-Inertia Analysis (MCIA) | Identifies co-relationships between multiple high-dimensional datasets; projects diverse data types into shared dimensional space [51] | Does not require feature annotation across all datasets; implemented in R/Bioconductor "omicade4" package |
| Data Integration Platforms | Airbyte | Open-source data integration with 600+ connectors; enables building custom data pipelines from multiple sources [52] | Flexible deployment options; avoids vendor lock-in |
| Cell Authentication | ATCC STR Profiling | Authenticates cell lines using standardized short tandem repeat analysis; ensures biological material validity [50] | Critical for preventing irreproducibility from misidentified or cross-contaminated cell lines |
| Statistical Tools | R/Bioconductor | Provides comprehensive statistical analysis capabilities; includes specialized packages for omics data analysis [51] | Enables implementation of linear models for cycle bias correction [7] |
| Data Repositories | Gene Expression Omnibus (GEO) | Public repository for functional genomics data; essential for accessing external datasets and sharing results [48] | Facilitates analytic replication and meta-analysis |
Troubleshooting Common Experimental Challenges
Frequently Asked Questions
Q1: Why did we identify significantly fewer candidate genes than expected in our endometriosis transcriptomic study?
- Potential Cause: Menstrual cycle phase may be masking true disease-associated genes. When studies are balanced in the proportion of samples collected at different endometrial stages or only in the mid-secretory phase, cycle bias can still obscure results [7].
- Solution: Apply linear models to explicitly correct for menstrual cycle phase as a confounding variable. This approach has been shown to reveal 44.2% more genes on average and discovered hundreds of novel candidate genes for endometriosis that were previously masked [7].
- Prevention: In study design, document cycle phase for all samples through histological dating and include phase as a covariate in all analytical models.
Q2: How can we integrate transcriptomic and proteomic data when correlation between platforms is lower than expected?
- Potential Cause: Poor correlation between transcripts and their corresponding proteins may reflect biological processes like microRNA post-transcriptional repression rather than technical artifacts [51].
- Solution: Use multivariate integration methods like Multiple Co-Inertia Analysis (MCIA) that do not require mapping features to a common set of identifiers. MCIA can identify co-relationships between datasets even when correlations are low and can extract important features not present across all platforms [51].
- Verification: Apply integrated analysis to known pathways; successful integration should increase coverage and power of pathway analysis, potentially revealing important pathways not highly ranked in individual dataset analyses [51].
Q3: Our replication study failed to reproduce previously published findings. What are the most common factors we should investigate?
- Potential Cause: The 2016 Nature survey on reproducibility found that over 70% of researchers could not reproduce others' findings, with these leading factors [50]:
- Pressure to publish (62% indicate it always/very often contributes)
- Poor experimental design and insufficient methodological details
- Use of misidentified or cross-contaminated cell lines
- Inability to manage complex datasets
- Cognitive biases in data interpretation
- Solution:
- Documentation: Publish negative results to help interpret positive results from related studies and adjust experimental design [50].
Q4: What data integration approach should we choose for combining cycle phase data with multiple molecular profiling datasets?
- Analysis: The choice depends on your specific data characteristics and research objectives:
- For exploratory analysis of multiple omics datasets: Multiple Co-Inertia Analysis (MCIA) simultaneously projects several datasets into the same dimensional space, transforming diverse features onto the same scale [51].
- For structured data pipelines: ETL (Extract, Transform, Load) processes clean, standardize, and load data into centralized repositories for analysis [47] [53].
- For real-time processing needs: ELT (Extract, Load, Transform) loads raw data first, then transforms it within the target system, better accommodating streaming data [52].
- Implementation: For cycle-aware analysis, ensure menstrual phase is included as a core dimension in all integration approaches, and use methods that preserve cyclic nature in temporal data [54].
Q5: How can we improve the reproducibility of our cell cycle experiments in cancer model systems?
- Potential Cause: Multiple factors affect reproducibility in life science research, including use of over-passaged cell lines, poor experimental design, and inadequate statistical training [50].
- Solution:
- Use authenticated, low-passage reference materials to ensure biological consistency [50]
- Implement robust data governance focusing on availability, usability, integrity, and security [53]
- Provide training on proper statistical methods and experimental design [50]
- Thoroughly describe methods including blinding, replicates, statistical analysis, and data inclusion/exclusion criteria [50]
- Validation: The Cell Cycle Database provides a resource for comparing mathematical models of cell cycle processes and simulating quantitative behavior of components over time [48].
Advanced Data Integration Techniques
Multifactorial Data Integration Pipeline
For complex studies integrating cycle data with multiple molecular profiling platforms, the following computational pipeline provides a robust approach.
Multifactorial Data Integration Pipeline
This pipeline highlights several advanced integration concepts:
- Multiple Co-Inertia Analysis (MCIA): This method identifies co-relationships between multiple high-dimensional datasets by simultaneously projecting them into the same dimensional space. It transforms diverse sets of features onto the same scale without requiring feature annotation across all datasets [51].
- Cycle Bias Correction: Linear models explicitly model and remove menstrual cycle effects, revealing genuine disease-associated signals [7].
- Pathway-Centric Interpretation: Integrated analysis often reveals pathways that weren't highly ranked in individual dataset analyses, providing more biologically meaningful insights [51].
Quantitative Framework for Assessing Integration Success
Table 3: Metrics for Evaluating Data Integration Success in Cycle Studies
| Evaluation Dimension | Specific Metric | Target Performance | Interpretation |
|---|---|---|---|
| Statistical Power | Percentage increase in identified genes after cycle correction | >44% improvement | Matches performance demonstrated in endometrial studies after menstrual cycle bias correction [7] |
| Pathway Coverage | Number of pathways identified with increased coverage | Significant increase | Integrated analysis should increase breath and coverage of biological pathways compared to single-platform analyses [51] |
| Data Reproducibility | Success rate of direct replication attempts | Alignment with field norms | 72% of biomedical researchers believe there's a reproducibility crisis; 27% perceive it as "significant" [49] |
| Technical Validation | Correlation between technical replicates | R > 0.95 | High reproducibility in molecular measurements ensures observed effects are biological rather than technical |
| Clinical Relevance | Predictive value in independent validation cohort | AUC > 0.75 | Biomarkers should generalize to new patient populations with good discriminatory power |
Proving the Paradigm: Quantifying the Impact of Bias Correction on Discovery Power
Transcriptomic approaches are powerful tools for identifying candidate endometrial biomarkers for uterine disorders such as endometriosis, recurrent implantation failure (RIF), and recurrent pregnancy loss (RPL). However, a significant confounding factor in these studies is the natural progression of the menstrual cycle, which introduces substantial molecular changes that can mask genuine disorder-related signals. When researchers fail to account for this cyclic variation, they risk both overlooking true biomarker candidates and identifying false positives linked to cycle stage rather than pathology. A systematic review of current practices revealed that approximately 31.43% of studies do not register the menstrual cycle phase of collected samples, potentially compromising their findings [7].
The impact of this oversight is quantifiable and substantial. Analytical work has demonstrated that correcting for menstrual cycle bias reveals, on average, 44.2% more candidate genes than analyses that do not account for this confounding effect. This correction increases statistical power, enabling the discovery of hundreds of novel candidate genes, including 544 for eutopic endometriosis, 158 for ectopic ovarian endometriosis, and 27 for recurrent implantation failure [7]. This technical support guide provides detailed methodologies and troubleshooting advice to help researchers implement effective bias correction protocols in their biomarker discovery workflows.
Technical Support & Troubleshooting Guides
Frequently Asked Questions (FAQs)
Q1: Why is menstrual cycle correction necessary if my study is already balanced in its sample collection across cycle phases? A: Even studies balanced in their proportion of samples collected across different endometrial stages can suffer from masking of true disease signals. The molecular changes driven by the cycle are so pronounced that they can obscure more subtle pathology-related changes. Applying a correction method, such as the linear models described, increases statistical power and has been shown to identify more candidate genes compared to independent per-phase analyses [7].
Q2: What is the fundamental source of bias in genetic effect estimation after a gene-based test? A: This bias, often termed "winner's curse" or "selection bias," arises from conditioning on statistical significance. When you first conduct a gene-based test and then perform single-marker analyses only on significant genes, the effect sizes for the individual variants are systematically overestimated. This happens because the same data is used for both significance testing and parameter estimation [55].
Q3: Are there other types of bias I should consider in genomic studies?
A: Yes. Beyond winner's curse and menstrual cycle bias, index event bias is a key concern in genome-wide association studies (GWAS) of subsequent events like prognosis or survival. This bias occurs when selecting subjects based on disease status (the index event), which can create spurious associations if common causes of incidence and prognosis are not accounted for [56]. Another is the systematic overestimation of marker heritability (p and h²) for large-effect loci, a cryptic bias unrelated to selection bias [57].
Q4: My single-marker effect sizes are likely inflated by winner's curse. What correction methods are available? A: Several methods exist:
- Bootstrap Resampling: A method where bootstrap samples are used to estimate the bias of the naïve (inflated) estimator. A bias-corrected estimate is then derived by subtracting the estimated bias from the naïve estimate. This approach has been shown to significantly reduce bias and improve variant prioritization [55].
- Independent Replication Sample: Using a completely different sample for parameter estimation than was used for the initial significant test. This is considered the gold standard but is often impractical due to cost and the population-specific nature of some rare variants [55].
- Sample-Splitting: Splitting the initial dataset into a discovery set (for testing) and a hold-out set (for estimation). This reduces bias but also reduces statistical power for the initial test [55].
Troubleshooting Common Experimental Issues
Problem: Low Number of Significant Biomarkers After Differential Expression Analysis.
- Potential Cause: Menstrual cycle progression is acting as a confounding variable, masking true disorder-related differential expression.
- Solution: Incorporate the menstrual cycle phase as a covariate in a linear model. Re-analyze the data after this correction.
- Expected Outcome: One study applying this method found an average increase of 44.2% more genes identified, significantly enhancing the discovery of candidate biomarkers for conditions like endometriosis and RIF [7].
Problem: Overestimated Effect Sizes for Genetic Variants in Post-Hoc Analysis.
- Potential Cause: Winner's curse bias, stemming from conditioning variant analysis on a significant gene-based test result.
- Solution: Apply a bootstrap resampling bias correction method. This involves:
- Generating multiple bootstrap samples from your original data.
- Re-performing the gene-based test and subsequent single-marker analysis on each sample.
- Using the distribution of effect sizes across all bootstrap samples to estimate and correct the bias in your original estimate [55].
- Expected Outcome: Studies show this method can lead to a two-fold decrease in bias on average (p < 2.2 × 10⁻⁶), substantially improving the mean squared error and the accuracy of variant prioritization [55].
Problem: Spurious Genetic Associations in a GWAS of Disease Prognosis.
- Potential Cause: Index event bias, where selection of subjects based on disease incidence creates correlated associations between genetic causes of incidence and prognosis.
- Solution: Implement the residual-based adjustment method [56].
- For a genome-wide set of independent (LD-pruned) SNPs, obtain their estimated effects on incidence (
β_GX) and their estimated effects on prognosis conditional on incidence (β'_GY). - Regress the prognosis effects (
β'_GY) on the incidence effects (β_GX). The slope (b) of this regression estimates the bias. - Adjust the prognosis effect for each SNP:
β_GY = β'_GY - b * β_GX.
- For a genome-wide set of independent (LD-pruned) SNPs, obtain their estimated effects on incidence (
- Expected Outcome: This method can reverse paradoxical associations. For example, in a study of idiopathic pulmonary fibrosis, it reversed a paradoxical association of the MUC5B gene with increased survival, revealing a true significant association with decreased survival [56].
Experimental Protocols & Data Presentation
Key Bias-Correction Workflows
The following diagrams illustrate the core protocols for correcting two major types of bias in genomic studies.
Diagram 1: Workflow for correcting menstrual cycle bias in endometrial biomarker studies.
Diagram 2: Workflow for correcting winner's curse bias in post-hoc genetic variant analysis.
Quantitative Gains from Bias Correction
Table 1: Impact of Menstrual Cycle Bias Correction on Gene Discovery
| Uterine Disorder Studied | Novel Candidate Genes Identified After Bias Correction | Key Finding |
|---|---|---|
| Eutopic Endometriosis | 544 genes | Correction reveals disorder-specific signals previously masked by cycle-stage expression. |
| Ectopic Ovarian Endometriosis | 158 genes | Enables distinction of pathology-related genes from normal cyclic molecular changes. |
| Recurrent Implantation Failure (RIF) | 27 genes | Increases statistical power to detect more subtle, but clinically relevant, expression changes. |
| Overall Average | 44.2% more genes | Linear model correction yields more candidate genes than per-phase independent analysis. [7] |
Table 2: Statistical Improvements from Bias Correction Methods in Genetic Analyses
| Bias Type | Correction Method | Quantitative Improvement |
|---|---|---|
| Winner's Curse (post-hoc variant effect estimation) | Bootstrap Resampling | Two-fold decrease in bias on average (p < 2.2 × 10⁻⁶); substantial improvement in mean squared error. [55] |
Marker Heritability (p and h²) Overestimation |
Average Semivariance Method | Yields unbiased estimates of the fraction of marker-associated genetic variance and heritability, unlike commonly used methods. [57] |
| Index Event Bias (in GWAS of prognosis) | Residual-based Adjustment | Reversed a paradoxical association, correctly identifying a susceptibility gene's link to decreased survival. [56] |
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Resources for Biomarker Discovery and Validation
| Resource Category | Function / Application | Examples / Key Features |
|---|---|---|
| Standardized Data & Analysis Platforms | Provides curated, standardized public data and analysis tools to contextualize findings and reduce data preprocessing noise. | QIAGEN Digital Insights: Access to hundreds of thousands of curated public datasets and knowledge graphs of gene-protein-disease relationships. [58] |
| AI-Powered Discovery Tools | Accelerates the discovery and prioritization of biomarkers by analyzing vast amounts of biomedical literature and data to uncover hidden connections. | Causaly AI: Analyzes hundreds of millions of data points to generate transparently sourced landscapes of genes and proteins implicated in a disease. [59] |
| Biomarker Repositories | Provides access to well-characterized biological samples crucial for biomarker validation. | NINDS BioSEND: Banks and distributes biospecimens (DNA, plasma, CSF) for neurological diseases. NINDS Human Cell and Data Repository: Provides iPSC lines for diseases like Parkinson's and ALS. [60] |
| Biomarker Validation Programs | Offers a pathway for rigorous validation of biomarkers as fit-for-purpose tools for use in clinical trials and therapeutic development. | FDA Biomarker Qualification Program (BQP): Works with stakeholders to develop biomarkers as drug development tools. [60] |
In endometrial biomarker discovery, a major technical challenge is isolating true disorder-specific signals from the substantial molecular noise caused by the natural menstrual cycle. Research demonstrates that menstrual cycle progression can mask molecular biomarkers, leading to both false positives and false negatives in your data. One systematic review found that approximately 31.43% of studies did not register the menstrual cycle phase of collected samples, fundamentally compromising their findings [7]. Fortunately, implementing proper experimental designs and statistical corrections can unmask these hidden signals—one study reported identifying 44.2% more candidate genes after effectively removing menstrual cycle bias using linear models [7].
Troubleshooting Guides
Guide 1: Addressing Excessive Uterine Gene Variability in Case-Control Studies
- Problem: High variability in transcriptomic data from endometrial samples obscures genuine differences between case and control groups.
- Root Cause: The primary culprit is often unaccounted-for menstrual cycle stage variation across your sample collection. The endometrial tissue undergoes profound molecular changes throughout the cycle, creating a confounding signal that can overwhelm more subtle disorder-related expression patterns [7].
- Solution:
- Stratified Sampling: Design your study to ensure cases and controls are perfectly matched for menstrual cycle phase (e.g., all in mid-secretory phase).
- Phase Verification: Do not rely on patient self-reporting alone. Confirm histological dating of the endometrial tissue according to established standards (e.g., Noyes' criteria) [7].
- Statistical Correction: If perfect matching is impossible, apply a statistical correction for menstrual cycle phase during your data analysis. Using linear models to remove the cycle effect has been proven to significantly increase statistical power and the number of identifiable candidate genes [7].
Guide 2: Handling Inconsistent Biomarker Performance Across Independent Cohorts
- Problem: A biomarker signature validated in one patient cohort fails to replicate in another.
- Root Cause: Inconsistent preanalytical handling of samples and differences in how the menstrual cycle phase is recorded or controlled for between cohorts. Variations in sample collection, storage, and platform effects can also contribute, but biological confounding is a primary suspect [23] [7].
- Solution:
- Standardize Protocols: Implement and document standardized SOPs for sample collection, processing, and storage across all study sites [23].
- Meta-Analysis with Adjustment: When pooling data from multiple cohorts (meta-analysis), apply a uniform menstrual cycle bias correction method to each dataset before combining them. This ensures the cycle effect does not create incoherent signals across the pooled data [7].
- Covariate Adjustment: In your predictive model, include the menstrual cycle phase as a key covariate. This helps the model distinguish between variation due to the cycle and variation due to the pathology of interest [23].
Guide 3: Differentiating True Biomarkers from Cycle-Associated Genes
- Problem: It is unclear whether a newly identified candidate gene is genuinely associated with the disorder or simply a reflection of the menstrual cycle stage.
- Root Cause: Lack of a clear framework to classify genes based on their expression patterns across different conditions and cycle phases.
- Solution:
- Profile in Healthy Controls: First, establish a baseline by profiling the expression of your candidate gene across all phases of the menstrual cycle in healthy control tissue.
- Implement a Classification Framework: Adopt a classification system that distinguishes biomarker types based on their behavior. The table below outlines a proposed classification based on the findings of Devesa-Peiro et al. [7]:
Table: Classification Framework for Candidate Biomarkers
| Biomarker Category | Expression in Disorder vs. Healthy Control | Expression Across Menstrual Cycle | Interpretation |
|---|---|---|---|
| Disorder-Specific | Significantly different | No significant change | Ideal biomarker; specific to the pathology. |
| Cycle-Associated | No significant difference | Significantly different | Not a disorder biomarker; reflects normal biology. |
| Mixed | Significantly different | Significantly different | Requires cycle-phase-matched analysis for validation. |
Guide 4: Validating a Multimodal Biomarker Signature
- Problem: Integrating diverse data types (e.g., clinical, genomic, proteomic) into a single biomarker signature, while accounting for menstrual cycle effects.
- Root Cause: Different data modalities may be influenced by the menstrual cycle to varying degrees, creating complex confounding. The "p >> n" problem (many more features than samples) common in omics data exacerbates this issue [23].
- Solution:
- Choose an Integration Strategy: Select a data integration method suitable for your goal.
- Early Integration: Combine raw data from all sources first, then extract features.
- Intermediate Integration: Use models like multimodal neural networks to join data sources during analysis [23].
- Late Integration: Analyze each data type separately and combine the results or predictions at the end [23].
- Assess Added Value: Compare the performance of your multimodal model against a baseline model that uses only traditional clinical data (including cycle phase) to determine if the new high-dimensional data provides a significant improvement [23].
- Cross-Validation: Use rigorous nested cross-validation to ensure your model, which includes cycle phase correction, generalizes well to new, unseen data [23].
- Choose an Integration Strategy: Select a data integration method suitable for your goal.
Frequently Asked Questions (FAQs)
Q1: What is the minimum sample size required to control for menstrual cycle bias? There is no universal minimum, as it depends on effect sizes. However, the key is to ensure your study is adequately powered. Use dedicated sample size determination methods [23] and ensure balanced sampling across the key comparison groups (cases/controls) and across menstrual cycle phases to avoid confounded results.
Q2: Can I use statistical correction instead of phase-matching during sample collection? While statistical correction (e.g., using linear models) is powerful and can rescue data from imperfectly matched studies, it is not a substitute for good study design. The most robust strategy is to prospectively match cases and controls for cycle phase during the design stage. Statistical correction should be viewed as a necessary secondary step to handle residual variation [7].
Q3: How do I validate that my correction for menstrual cycle bias has worked? The success of bias correction can be measured by a significant increase in the number of robust, disorder-associated candidate genes identified after correction. Furthermore, you should check that known, well-established cycle-phase marker genes are no longer significant in your differential expression analysis between cases and controls after the correction has been applied [7].
Q4: Are there specific technologies best suited for controlling this bias? The bias is biological, not technological. However, technologies that allow for highly multiplexed and precise measurements from small sample volumes (e.g., NanoString for transcriptomics or mass spectrometry for proteomics) are beneficial. They enable you to gather more data points from a single, well-characterized sample, making it easier to model and subtract unwanted variation [61] [62].
Q5: What are the regulatory considerations for biomarkers developed with cycle bias correction? Regulatory bodies like the FDA and EMA emphasize biomarker validation and qualification. This process requires confirming that a biomarker is reliable, reproducible, and accurately predicts clinical outcomes. Providing robust evidence that you have controlled for major confounders like the menstrual cycle will strengthen your regulatory submission [63]. Clearly document your sampling strategy, correction methods, and performance metrics.
Experimental Protocols & Data
Core Protocol: Correcting Menstrual Cycle Bias Using Linear Models
This protocol is adapted from the method demonstrated to unmask 44.2% more genuine candidate genes [7].
- Sample Collection & Phase Determination: Collect endometrial biopsies from meticulously phenotyped case and control participants. Histologically date each sample according to standardized criteria (e.g., Noyes' criteria) to assign a precise cycle phase.
- Transcriptomic Profiling: Perform RNA extraction and sequencing (e.g., RNA-Seq) or targeted gene expression analysis (e.g., NanoString) on all samples.
- Data Preprocessing: Conduct standard quality control (e.g., using
arrayQualityMetrics[23]), normalization, and log2 transformation of the gene expression data. - Model Fitting: For each gene, fit a linear model of the form:
Expression ~ Group + Menstrual_Cycle_Phase + (Optional Covariates)where "Group" is the case/control status. - Bias Correction: Extract the effect of the "Group" variable from the model. This represents the disorder-specific gene expression effect, independent of the variation explained by the "MenstrualCyclePhase."
- Differential Expression Analysis: Identify significantly differentially expressed genes based on the corrected "Group" effect, using a false discovery rate (FDR) correction for multiple testing (e.g., Benjamini-Hochberg procedure [61]).
Quantitative Impact of Bias Correction
Table: Impact of Menstrual Cycle Bias Correction on Gene Discovery
| Study Focus | Genes Found Without Correction | Additional Genes Found After Correction | Percentage Increase | Source |
|---|---|---|---|---|
| Eutopic Endometriosis | Information missing | 544 novel candidates | -- | [7] |
| Ovarian Endometriosis | Information missing | 158 novel candidates | -- | [7] |
| Recurrent Implantation Failure | Information missing | 27 novel candidates | -- | [7] |
| Pooled Analysis of 12 Studies | Baseline | -- | +44.2% more genes on average | [7] |
The Scientist's Toolkit
Table: Essential Reagents & Resources for Endometrial Biomarker Studies
| Item | Function/Description | Example/Note |
|---|---|---|
| Histological Staining Reagents | To confirm menstrual cycle phase of endometrial tissue biopsies via histology. | Hematoxylin and Eosin (H&E) stain, following Noyes' criteria. |
| RNA Stabilization Reagent | To preserve RNA integrity immediately upon biopsy collection for transcriptomics. | RNAlater or similar commercial reagents. |
| Linear Modeling Software | To perform the statistical correction for menstrual cycle phase. | R statistical environment with the limma package [61]. |
| Quality Control Software | To assess data quality before and after preprocessing of raw omics data. | fastQC for NGS data, arrayQualityMetrics for microarrays [23]. |
| Secreted Gene Database | A library of genes encoding secreted proteins to filter for potential blood-based biomarkers. | As used by Vathipadiekal et al. to identify serum biomarkers like FGF18 [61]. |
| Heavy Isotope-Labeled Peptides | For absolute quantification and validation of protein biomarkers using SRM/MRM mass spectrometry. | Used as internal standards to distinguish target peptides from non-specific signals [62]. |
Visualizing Workflows and Concepts
Experimental Workflow for Bias-Aware Biomarker Discovery
Classifying Biomarker Candidates Post-Correction
In the field of reproductive medicine, transcriptomic approaches are increasingly used to identify candidate endometrial biomarkers for conditions like uterine fibroids (UFs) and recurrent implantation failure (RIF). However, a significant confounding variable—menstrual cycle progression—profoundly influences endometrial gene expression and can mask the discovery of disorder-related genes [1].
Research demonstrates that menstrual cycle progression has a substantial effect on biomarker identification. A systematic review found that 31.43% of transcriptomic studies did not register the menstrual cycle phase of endometrial samples, potentially compromising their findings [1]. When menstrual cycle bias was corrected using linear models, an average of 44.2% more genes were identified across studies evaluating endometriosis, RIF, and uterine fibroids [1] [7].
This technical guide explores how correcting for menstrual cycle bias enhances gene discovery for uterine fibroids and RIF, providing methodologies, troubleshooting advice, and practical solutions for researchers in women's health.
Quantitative Comparison: Bias-Corrected vs. Traditional Methods
The table below summarizes the quantitative advantages of implementing menstrual cycle bias correction in genomic studies of uterine disorders.
Table 1: Impact of Menstrual Cycle Bias Correction on Gene Discovery
| Research Aspect | Traditional Methods (Uncorrected) | Bias-Corrected Methods | Key Improvement |
|---|---|---|---|
| Overall Gene Discovery | Limited identification of disorder-related genes | Average of 44.2% more genes identified [1] | Vastly improved detection capability |
| Uterine Fibroid Biomarkers | Reliance on imaging (ultrasound/MRI) for diagnosis [64] | Potential biomarkers: PLP1, FOS, versican, LDH, IGF-1 identified [64] | Molecular-based early detection |
| RIF Gene Discovery | Limited, inconsistent candidate genes | 544 novel candidate genes for eutopic endometriosis; 27 for RIF [1] | Deeper understanding of molecular bases |
| Statistical Power | Reduced due to confounding variables | Increased statistical power retrieving more candidate genes [1] | More reliable research outcomes |
| Study Design Consideration | 31.43% of studies don't register cycle phase [1] | Explicit accounting for cycle phase in design | Improved research quality |
Experimental Protocols for Bias Correction
Menstrual Cycle Effect Correction and Differential Expression Analysis
Principle: The effect of menstrual cycle progression on endometrial biopsy collection is removed from gene expression data while preserving condition-related differences (e.g., uterine disorder vs. control) [1].
Step-by-Step Protocol:
- Data Pre-processing: Normalize between samples using quantile normalization (
limmaR package v.3.30.13). For RNA-Seq data, perform low-count filtering and normalization withedgeRR package v.3.16.5 [1]. - Exploratory Analysis: Perform principal component analysis (PCA) to visualize menstrual cycle effect. Compare proportion of biopsies collected at different cycle stages between case and control groups using Fisher's exact test [1].
- Bias Correction: Use the
removeBatchEffectfunction based on linear models implemented in thelimmaR package v.3.30.13. Specify:batch: Menstrual cycle phase of endometrial biopsy collectiondesign matrix: Condition to be preserved (case vs. control samples) [1]
- Differential Expression Analysis: Apply case versus control differential expression analyses with and without removing menstrual cycle effect using
limmaR package. Compare proportions of differentially expressed genes (FDR < 0.05) to demonstrate bias impact [1].
Technical Note: The removeBatchEffect function is recommended as a "slightly safer option than Combat," specifically for correcting known batch effects like menstrual cycle while preserving group differences of interest [1].
Integrated Bioinformatics Workflow for Shared Molecular Landscapes
Application: For identifying shared pathways between uterine fibroids and RIF.
Table 2: Key Research Reagent Solutions for Transcriptomic Analysis
| Reagent/Resource | Function/Purpose | Example Specifications |
|---|---|---|
| Endometrial Biopsy Samples | Source of RNA for transcriptomic analysis | Collected during mid-secretory phase (LH+5 to LH+8) [65] |
| RNA Extraction Kits | Isolation of high-quality total RNA | Qiagen RNeasy Mini Kits [65] |
| Microarray Platforms | Genome-wide gene expression profiling | Affymetrix, Illumina, or Agilent platforms [1] |
| RNA-Seq Library Prep | Preparation of transcriptome libraries | MARS-seq method; barcoding and reverse transcription [65] |
| R/Bioconductor Packages | Statistical analysis of differential expression | limma, edgeR, affy [1] |
Workflow Steps:
- Data Acquisition: Obtain gene expression and methylation datasets from public repositories (e.g., GEO: GSE64763, GSE92324, GSE120854) [66].
- Differential Analysis: Identify differentially expressed genes (DEGs) and differentially methylated genes (DMGs) using thresholds (e.g., |log2 fold change| > 1, |delta beta| > 0.15, adjusted p-values < 0.05) [66].
- Co-expression Network Analysis: Apply Weighted Gene Co-expression Network Analysis (WGCNA) to identify modules of highly correlated genes. Select key genes using criteria (e.g., |gene significance| ≥ 0.50 and |module membership| ≥ 0.80) [66].
- Integration: Extract shared genes between DEGs, DMGs, and WGCNA key genes to identify core candidate genes [66].
Troubleshooting Guides & FAQs
Common Experimental Challenges and Solutions
Table 3: Troubleshooting Common Issues in Menstrual Cycle Bias Correction
| Problem | Potential Cause | Solution | Prevention |
|---|---|---|---|
| Inconsistent results between studies | Unregistered menstrual cycle phase in sample collection [1] | Re-analyze data with menstrual cycle bias correction | Document cycle phase for all samples using LH peak dating or histology |
| Poor overlap with published biomarkers | Menstrual cycle effect masking true disorder-related genes [1] | Apply linear models to remove cycle effect while preserving case-control differences | Include cycle phase as covariate in initial experimental design |
| Weak statistical power | High variability from unaccounted cycle progression [1] | Use bias correction method rather than per-phase independent analysis | Balance sample collection across cycle phases for case and control groups |
| Physical inconsistency in corrected data | Over-aggressive statistical correction disrupting biological relationships | Validate findings with protein-level analysis (e.g., IHC) [65] | Use methods that preserve physical relationships between variables |
Frequently Asked Questions
Q: Why is menstrual cycle phase so important in endometrial biomarker studies? A: The human endometrium is hormonally regulated and changes dramatically throughout the menstrual cycle molecularly. During most of the cycle, the endometrium is not receptive to embryonic implantation; it becomes receptive only during a brief window of implantation within the mid-secretory phase. This profound biological changes significantly influence gene expression patterns [1] [65].
Q: Can I just collect all samples in the mid-secretory phase to avoid cycle variation? A: While collecting samples in a single phase reduces some variability, studies show that menstrual cycle bias persists even when analyses are limited to the mid-secretory phase. The molecular progression within this phase still introduces confounding effects that can mask disorder-related genes [1].
Q: What if my sample size is too small for batch effect correction? A: For very small sample sizes, consider integrating your data with publicly available datasets from repositories like GEO. This approach increases statistical power and allows for more robust bias correction. Several recent studies have successfully used this method to identify molecular subtypes of RIF [65].
Q: How do I validate that my bias correction worked without removing biological signals of interest? A: Use positive control genes known to be associated with your disorder of interest. For RIF research, recently identified subtype-specific markers like immune signatures for RIF-I or metabolic genes for RIF-M can serve as validation targets [65]. Protein-level validation using immunohistochemistry is also recommended [65].
Q: Are there specific genes whose discovery is enhanced by bias correction? A: Yes, studies have identified numerous additional genes after menstrual cycle bias correction. For instance, after correction, researchers discovered 544 novel candidate genes for eutopic endometriosis, 158 genes for ectopic ovarian endometriosis, and 27 genes for recurrent implantation failure that were previously masked [1]. For uterine fibroids, biomarkers like PLP1 and FOS were identified through approaches controlling for confounding variables [64].
Pathway Diagrams and Molecular Relationships
Menstrual Cycle Bias Correction Workflow
Diagram 1: Bias Correction Workflow for endometrial biomarker studies. This workflow demonstrates the systematic approach to unmasking genes by correcting for menstrual cycle phase effects.
Shared Molecular Landscape Between Uterine Fibroids and RIF
Diagram 2: Shared molecular pathways between UFs and RIF. An integrated bioinformatics approach identified three key shared genes (EDNRB, BIRC3, TRPC6) through intersection of differential expression, methylation, and co-expression analyses [66].
Correcting for menstrual cycle bias is not merely a statistical refinement but a fundamental requirement for rigorous endometrial biomarker research. The evidence demonstrates that implementing bias correction methods reveals significantly more candidate genes for both uterine fibroids and recurrent implantation failure—with an average 44.2% improvement in gene detection [1].
By adopting the experimental protocols, troubleshooting guides, and analytical workflows outlined in this technical support document, researchers can overcome the confounding effects of menstrual cycle progression and accelerate the discovery of robust diagnostic biomarkers and therapeutic targets for uterine disorders.
In the field of endometrial biomarker discovery, methodological rigor is not merely a technical concern but a fundamental determinant of diagnostic and therapeutic success. The profound influence of the menstrual cycle on endometrial gene expression and molecular biology represents a significant confounding variable that, if unaddressed, obscures genuine pathological signatures and undermines research validity [1]. This technical support center provides actionable guidance for researchers to identify, correct, and prevent menstrual cycle bias, thereby enhancing the reliability and clinical translatability of their findings in reproductive medicine and beyond.
Frequently Asked Questions (FAQs)
Q1: What is menstrual cycle bias, and why does it matter in biomarker studies?
Menstrual cycle bias occurs when natural, cyclical changes in gene expression and protein levels within the endometrium mask or mimic the molecular signals associated with a uterine disorder. This is critical because it directly impacts the false discovery rate of candidate biomarkers. One systematic review found that failing to account for this effect led to an average of 44.2% fewer genes being identified as statistically significant [1] [7]. This bias is a primary reason why many biomarker studies show poor overlap and reproducibility.
Q2: How can I determine if my study is susceptible to this bias?
Your study is susceptible if it involves comparing endometrial samples from case and control groups without:
- Registering and accounting for the menstrual cycle phase at the time of sample collection.
- Ensuring a balanced distribution of cycle phases between compared groups. The review of 35 transcriptomic studies revealed that 31.43% did not register the menstrual cycle phase at all, introducing a major, unaddressed confounder [1].
Q3: What is the gold-standard method for tracking the menstrual cycle in research?
The gold standard involves prospective daily monitoring rather than retrospective recall. Key practices include:
- Tracking Cycle Day: Record the first day of menstrual bleeding as Cycle Day 1 [28].
- Confirming Ovulation: Use methods like urinary luteinizing hormone (LH) tests to pinpoint the ovulation day, which demarcates the follicular and luteal phases. The luteal phase has a more consistent length (average 13.3 days) than the follicular phase (average 15.7 days) [28].
- Hormone Measurement: In certain designs, directly measuring plasma levels of estradiol (E2) and progesterone (P4) provides objective phase confirmation [28].
Q4: My sample sizes are small. Can I still correct for cycle bias effectively?
Yes, statistical correction methods can be applied even with smaller sample sizes. Using linear models (e.g., the removeBatchEffect function in the limma R package) to mathematically remove the variation due to the cycle phase has been shown to increase statistical power, retrieving more candidate genes than analyzing each menstrual cycle phase independently [1]. This approach allows you to preserve statistical power while controlling for a major confounder.
Troubleshooting Guide: Common Scenarios and Solutions
| Problem | Root Cause | Solution |
|---|---|---|
| Poor overlap with published biomarkers | Menstrual cycle bias masks true disorder-related genes, leading to high rates of false positives and negatives. | Re-analyze your data and published datasets with menstrual cycle phase correction using linear models [1]. |
| Biomarker performs well in one cohort but fails validation | Biological and technical variability; differences in cycle phase distribution between cohorts. | Implement standard operating procedures (SOPs) for sample collection timing and processing. Perform technical verification in an independent cohort [67]. |
| High within-group variance in biomarker levels | Samples collected across different menstrual cycle phases are grouped together, introducing large physiological variation. | Re-stratify samples by accurately defined cycle phase and re-analyze. For future studies, use a within-subject design with multiple observations per participant across cycles [28]. |
| Weak or non-significant biomarker signal | The effect of the disorder on the biomarker is subtle and is being drowned out by the stronger signal of menstrual cycle progression. | Apply a menstrual cycle bias correction method. One study discovered 544 novel candidate genes for endometriosis only after this correction [1]. |
Detailed Experimental Protocols
Protocol 1: Statistical Correction for Menstrual Cycle Bias in Transcriptomic Data
This protocol is adapted from Devesa-Peiro et al. (2021) for using linear models to remove menstrual cycle bias from gene expression data while preserving the case-control differences of interest [1].
1. Pre-processing and Exploratory Analysis
- Normalization: Normalize raw gene expression data (from microarray or RNA-Seq) using standard packages (e.g.,
limmafor microarrays,edgeRfor RNA-Seq). - Batch Effect Correction: First, detect and correct for other technical batch effects (e.g., sequencing run, microarray slide) using linear models.
2. Menstrual Cycle Effect Correction
- Tool: Use the
removeBatchEffectfunction from thelimmaR package (v.3.30.13 or higher). - Inputs:
batch: The menstrual cycle phase (e.g., follicular, luteal) for each sample.design: The design matrix specifying the groups to be compared (e.g., case vs. control).
- Rationale: This function fits a linear model to the data and removes the variation associated with the specified batch (menstrual cycle phase), while preserving the variation associated with the design (your condition of interest).
3. Differential Expression Analysis
- Perform case versus control differential expression analysis on the corrected data using the
limmapackage. - Compare the results with an analysis performed on the uncorrected data to demonstrate the impact of bias correction.
The following workflow visualizes this bioinformatics pipeline:
Protocol 2: Prospective Menstrual Cycle Tracking for Laboratory Studies
For studies collecting new samples, proper phase tracking is essential. This protocol is based on best-practice recommendations for cycle research [28].
1. Participant Screening and Enrollment
- Include only naturally-cycling individuals.
- Exclude participants using hormonal medication or with surgical histories that affect cycling.
2. Cycle Monitoring and Phase Determination
- Cycle Day Tracking: Have participants record the first day of menstrual bleeding (Cycle Day 1) for at least one full cycle before sampling.
- Ovulation Confirmation: Provide participants with urinary LH test kits. The day of the LH surge is used to define the day of ovulation, separating the follicular and luteal phases.
- Phase Definitions:
- Mid-Follicular: ~Cycle Days 5-8 (low, stable E2 and P4).
- Periovulatory: ~1 day before to 1 day after ovulation (peaking E2, low P4).
- Mid-Luteal: ~5-9 days after ovulation (high P4, elevated E2).
- Perimenstrual: ~2 days before to 2 days after next menses onset (rapidly falling E2 and P4).
3. Sample Collection Timing
- Schedule sample collection based on the confirmed cycle phase, not just estimated cycle day.
- For a within-subject design, collect samples from the same participant at key phases (e.g., follicular and luteal) across one or, preferably, two cycles to increase reliability.
The relationship between hormone levels and cycle phases is fundamental to planning experiments:
Essential Computational Tools for Analysis
| Tool Name | Platform | Primary Function | Relevance to Biomarker Discovery |
|---|---|---|---|
| limma R Package | R | Linear models for microarray and RNA-Seq data | Correct for batch effects like menstrual cycle phase; perform differential expression analysis [1]. |
| pcvsuite | R/Stata | ROC curve analysis, comparison, and covariate adjustment | Evaluate and compare the diagnostic performance of candidate biomarkers [68]. |
| C-PASS (Carolina Premenstrual Assessment Scoring System) | Worksheet, Excel, R, SAS | Standardized diagnosis of PMDD and PME from daily ratings | Screen study participants for cyclical mood disorders that could confound results [28]. |
| ROC Analysis Software | SAS, SPSS | Plot ROC curves and calculate AUC | Standard assessment of biomarker classification performance [68]. |
Research Reagent Solutions
This table details key materials and assays used in rigorous endometrial biomarker studies.
| Item | Function / Application | Example / Note |
|---|---|---|
| Urinary LH Test Kits | At-home confirmation of ovulation for accurate menstrual cycle phase determination. | Critical for defining the luteal phase, which has a more consistent length than the follicular phase [28]. |
| EDTA Plasma Tubes | Collection of blood plasma for protein biomarker analysis. | Used with SOPs for processing (centrifuging within 1 hour, storage at -80°C) to minimize pre-analytical variation [67]. |
| Immunoassays (e.g., for CA-125, VEGF) | Quantification of specific protein biomarkers in plasma or serum. | Performance varies by manufacturer and lot; technical verification using the same assay is crucial for validation [67]. |
| RNA Stabilization Reagents | Preservation of RNA integrity from endometrial biopsy samples prior to transcriptomic analysis. | Essential for reliable gene expression profiling from endometrial tissue [1]. |
| Daily Record of Severity of Problems (DRSP) | Prospective daily rating of symptoms for defining Menstrual Cycle-Associated Syndrome (MCAS). | Used to validate new case definitions against biomarker levels like chemokines and oxidative stress markers [69]. |
Conclusion
Correcting for menstrual cycle bias is not merely a technical refinement but a fundamental necessity for advancing women's health research. The evidence demonstrates that failing to account for the dynamic molecular biology of the menstrual cycle significantly obscures genuine disease biomarkers, as exemplified by the revelation of hundreds of new candidate genes for endometriosis and recurrent implantation failure after bias correction. The methodologies and guidelines outlined provide a actionable path forward, empowering researchers to enhance the statistical power, accuracy, and clinical relevance of their findings. Embracing this cycle-aware paradigm is crucial for developing more precise diagnostics and effective, personalized treatments for uterine disorders. Future research must prioritize the integration of these corrective frameworks across all phases of biomarker discovery, from initial study design to final data analysis, to finally close the long-standing gender gap in biomedical research and deliver on the promise of equitable, personalized medicine for all.
References
- 1. Guidelines for biomarker discovery in endometrium [https://pmc.ncbi.nlm.nih.gov/articles/PMC8063681/]
- 2. Variation in serum biomarkers with sex and female ... [https://www.nature.com/articles/srep26947]
- 3. Failure to Consider the Menstrual Cycle Phase May Cause ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC3873842/]
- 4. Research progress in estrogen as an adjunctive therapy for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11964812/]
- 5. Association between menstrual cycle phase and metabolites ... [https://bmcmedicine.biomedcentral.com/articles/10.1186/s12916-023-03195-w]
- 6. Menstrual cycle rhythmicity: metabolic patterns in healthy ... [https://www.nature.com/articles/s41598-018-32647-0]
- 7. correcting for menstrual cycle bias reveals new genes ... [https://pubmed.ncbi.nlm.nih.gov/33576824/]
- 8. A molecular staging model for accurately dating the ... [https://www.nature.com/articles/s41467-023-41979-z]
- 9. The accuracy and reproducibility of the endometrial ... [https://www.sciencedirect.com/science/article/pii/S001502821202300X]
- 10. Time-series single-cell transcriptomic profiling of luteal ... [https://www.nature.com/articles/s41467-024-55419-z]
- 11. Uterine Transcriptome: Understanding Physiology and ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10136129/]
- 12. A spatial transcriptomics dataset of the endometrium from ... [https://www.nature.com/articles/s41597-025-05995-6]
- 13. Human Endometrial Transcriptomics: Implications for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC4484960/]
- 14. Women's Health The extent and causes of natural variation ... [https://www.sciencedirect.com/science/article/abs/pii/S1740675720300104]
- 15. UCI-led study challenges belief that menstrual cycles ... [https://www.socsci.uci.edu/newsevents/news/2023/2023-05-02-poor-sleep-to-blame-for-negative-mood-swings-during-menses.php]
- 16. Gender bias is still putting women's health at risk [https://www1.racgp.org.au/newsgp/clinical/gender-bias-in-medicine-and-medical-research-is-st]
- 17. Navigating menstrual stigma and norms: a qualitative study on ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11654398/]
- 18. This Innovation Could Revolutionize Reproductive Health ... [https://engineering.jhu.edu/chembe/news/this-innovation-could-revolutionize-reproductive-health-diagnostics-period/]
- 19. Discovering Composite Lifestyle Biomarkers With Artificial ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC8521973/]
- 20. Improving Replication in Endometrial Omics [https://www.mdpi.com/1422-0067/26/2/857]
- 21. Common Lab Issues That Impact Biomarker Data [https://blog.omni-inc.com/blog/common-lab-issues-that-impact-biomarker-data]
- 22. Biomarker Discovery and Validation: Statistical Considerations [https://pmc.ncbi.nlm.nih.gov/articles/PMC8012218/]
- 23. Ten quick tips for biomarker discovery and validation ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC9371329/]
- 24. Why Do Biomarkers Fail? [https://sonraianalytics.com/why-do-biomarkers-fail/]
- 25. Integrated Biomarker Discovery Workflow-Bioinformatics to ... [https://www.elucidata.io/blog/integrated-biomarker-discovery-workflow-bioinformatics-to-clinical-validation]
- 26. Whole-brain dynamics across the menstrual cycle [https://www.nature.com/articles/s44294-024-00012-4]
- 27. length variation by demographic characteristics from... Menstrual cycle [https://www.nature.com/articles/s41746-023-00848-1?error=cookies_not_supported&code=6cd9e3e3-4f08-4f68-bffa-ce8473b49930]
- 28. How to study the menstrual cycle - PubMed Central - NIH [https://pmc.ncbi.nlm.nih.gov/articles/PMC8363181/]
- 29. Predicting risk of endometrial failure: a biomarker signature ... [https://www.sciencedirect.com/science/article/pii/S0015028224001900]
- 30. Global endometrial DNA methylation analysis reveals ... [https://www.nature.com/articles/s42003-023-05070-z]
- 31. Update on Biomarkers for the Detection of Endometriosis [https://pmc.ncbi.nlm.nih.gov/articles/PMC4512573/]
- 32. Identification of hub biomarkers and immune cell ... [https://www.nature.com/articles/s41598-025-86164-y]
- 33. Tutorial: best practices and considerations for mass ... [https://www.nature.com/articles/s41596-021-00566-6]
- 34. The Strategy Behind Phased LIMS Implementation [https://thirdwaveanalytics.com/blog/phased-lims-implementation-strategy/]
- 35. Solid Phase Extraction Guide [https://www.thermofisher.com/us/en/home/industrial/chromatography/chromatography-sample-preparation/sample-preparation-consumables/solid-phase-extraction-consumables/spe-guide.html]
- 36. Statistical innovations in clinical trial design with a focus on ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12627888/]
- 37. Machine learning-based menstrual phase identification ... [https://www.nature.com/articles/s44294-025-00078-8]
- 38. 2025 Clinical Data Trend Report [https://www.veeva.com/2025-clinical-data-trend-report/]
- 39. Menstrual Cycle Phase Influences Cognitive Performance ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12384028/]
- 40. Menstrual cycle length variation by demographic ... [https://www.nature.com/articles/s41746-023-00848-1]
- 41. Reproducible stability of verbal and spatial functions along ... [https://www.nature.com/articles/s41386-023-01789-9]
- 42. Importance of cohort and target trial emulation in clinical ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12047467/]
- 43. A Review on Biomarker‐Enhanced Machine Learning for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12421415/]
- 44. Efficient Case-Cohort Design using Balanced Sampling [https://arxiv.org/html/2311.05914v2]
- 45. Successful Implementation of Menstrual Cycle Biomarkers ... [https://www.mdpi.com/2227-9032/11/4/616]
- 46. Survey Analysis of Quantitative and Qualitative Menstrual ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10534579/]
- 47. All You Need to Know about Data Integration in 2025 [https://www.aezion.com/blogs/data-integration-what-you-need-to-know/]
- 48. A data integration approach for cell cycle analysis oriented ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC1995223/]
- 49. Biomedical researchers' perspectives on the reproducibility ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC11537370/]
- 50. Six factors affecting reproducibility in life science research ... [https://www.nature.com/articles/d42473-019-00004-y]
- 51. A multivariate approach to the integration of multi-omics datasets [https://bmcbioinformatics.biomedcentral.com/articles/10.1186/1471-2105-15-162]
- 52. Top 10 Big Data Integration Tools in 2025 [https://airbyte.com/data-engineering-resources/big-data-integration]
- 53. Data Integration Solutions: Enterprise Guide 2025 [https://improvado.io/blog/enterprise-data-integration]
- 54. Detection and Visualization of Cyclic Multivariate Data [http://www.cs.wpi.edu/~matt/courses/cs563/talks/Cyclic_Presentation/index.html]
- 55. Illustrating, Quantifying, and Correcting for Bias in Post-hoc ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC5603735/]
- 56. Adjustment for index event bias in genome-wide ... [https://www.nature.com/articles/s41467-019-09381-w]
- 57. Average semivariance yields accurate estimates of the fraction ... [https://journals.plos.org/plosgenetics/article?id=10.1371/journal.pgen.1009762]
- 58. Biomarker Identification Tools [https://digitalinsights.qiagen.com/research-and-discovery/biomarker-identification/]
- 59. Biomarker Discovery [https://www.causaly.com/use-cases/biomarker-discovery]
- 60. Focus On Biomarkers Research [https://www.ninds.nih.gov/current-research/focus-tools-topics/focus-biomarkers-research]
- 61. Discovery and Validation of Novel Biomarkers for Detection ... [https://www.mdpi.com/2073-4409/8/7/713]
- 62. Modeling and systematic analysis of biomarker validation ... [https://bsb-eurasipjournals.springeropen.com/articles/10.1186/s13637-014-0017-y]
- 63. Biomarkers: Opportunities and Challenges for Drug ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC7727038/]
- 64. Genetic and biomarker approaches to uterine fibroids [https://pmc.ncbi.nlm.nih.gov/articles/PMC12052703/]
- 65. Molecular subtype of recurrent implantation failure reveals ... [https://translational-medicine.biomedcentral.com/articles/10.1186/s12967-025-06771-1]
- 66. Identifying shared molecular landscape between uterine ... [https://www.sciencedirect.com/science/article/pii/S2405844025013878]
- 67. Technical Verification and Assessment of Independent ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6683797/]
- 68. Software [https://research.fredhutch.org/diagnostic-biomarkers-center/en/software.html]
- 69. Biomarker Validation of a New Case Definition ... [https://pubmed.ncbi.nlm.nih.gov/32998680/]